






















In 2020, fewer than 25% of new applications were built with low-code or no-code tools. By 2026, Gartner expects that figure to reach 75%, a 3x shift in six years. Whatever you decide for your own product, building this way has already moved from the exception to the default. The rest of this guide is about whether it should be your default.
You have an app idea. You’ve been quoted $80,000 to build it. Then someone at a dinner mentions Bubble, or Webflow, or “just vibe-code it,” and says you can do the whole thing for a couple hundred dollars a month. Now you don’t know who to believe, the quote feels steep, the shortcut feels too good to be true, and you can’t tell which is right.
That confusion is the single most common starting point we see. So this guide does two things at once. First, it lays out what the market data actually says about low-code and no-code. Second, and more importantly, it translates each number into a decision you can actually make: Is this right for my business, at this stage, with my budget?
Key Takeaways
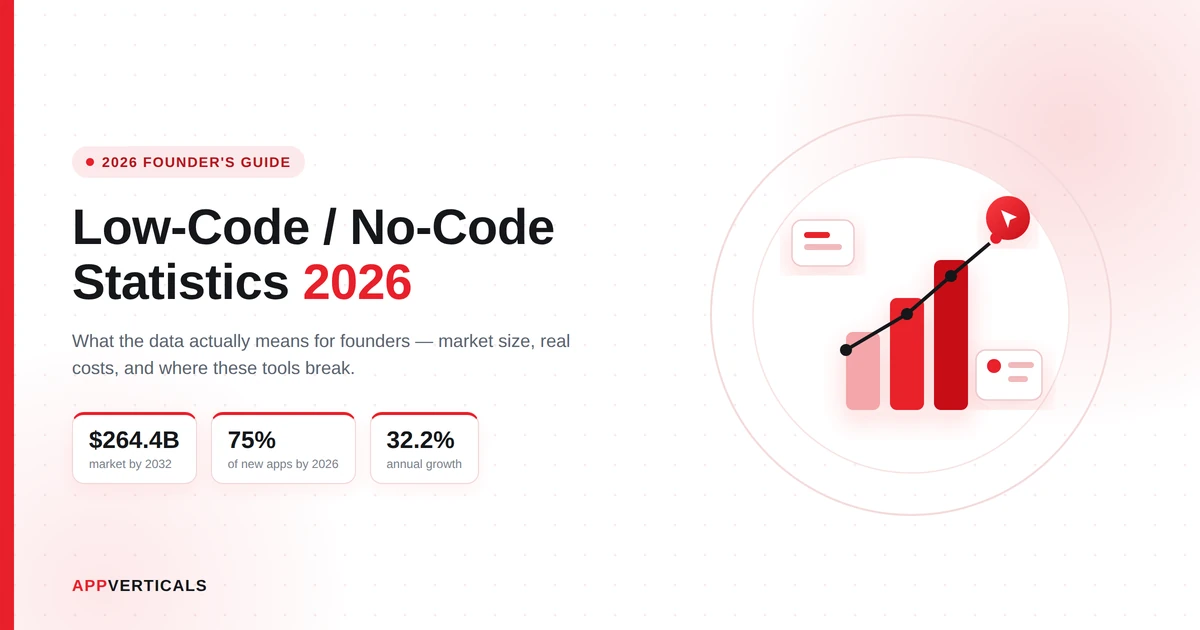
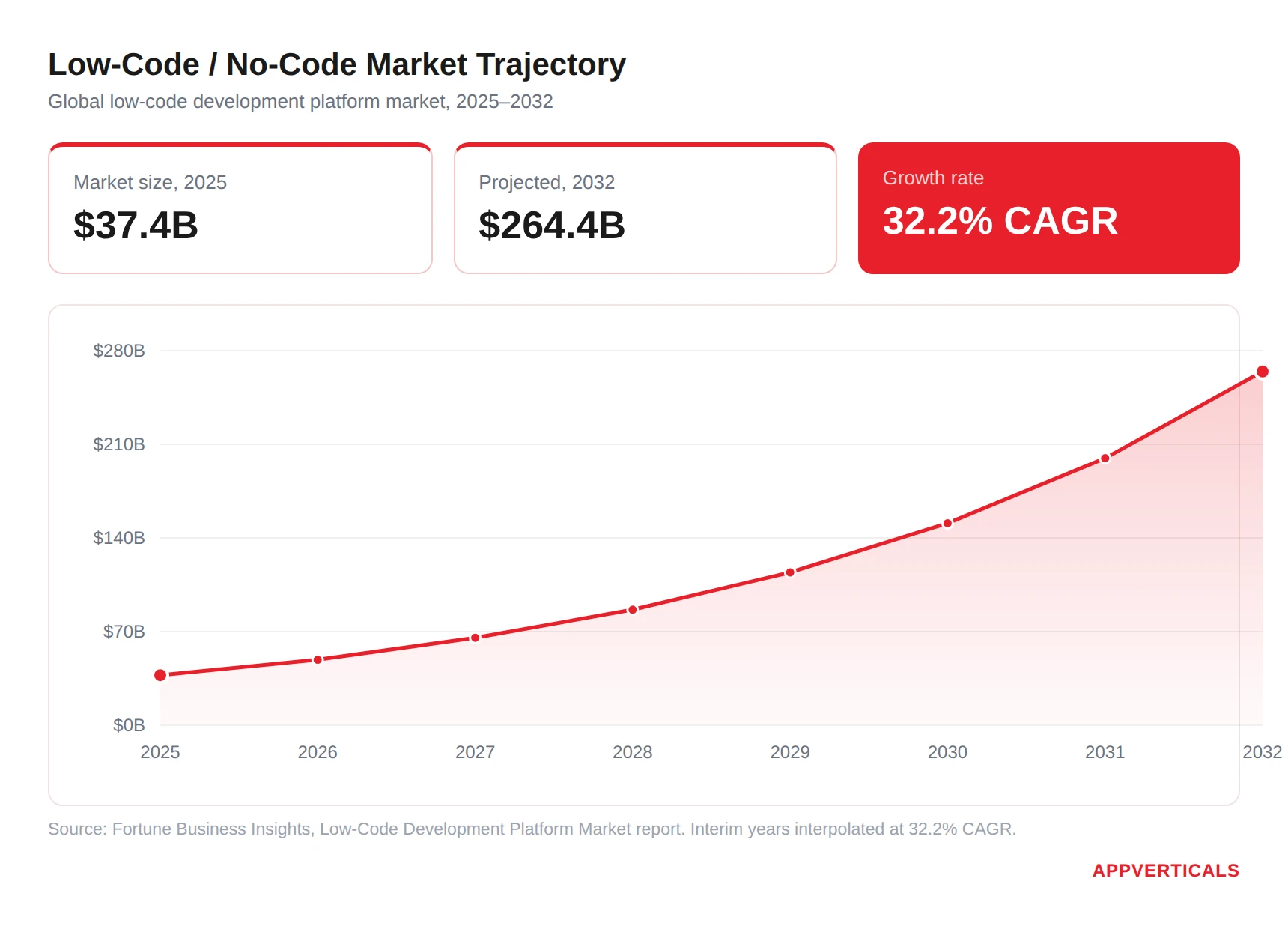
- Market size: The low-code development platform market stood at ~$37.4 billion in 2025, and is projected to hit $264.4 billion by 2032 at a 32.2% CAGR, though estimates vary widely by analyst, this is one of the higher-growth projections.
- Adoption: Gartner projects 70% of new applications would use low-code/no-code by the end of 2025 (up from <25% in 2020), rising to 75% by 2026.
- Speed: Low-code can cut development time by up to 90%; GitHub reports developers completing tasks 55% faster with AI assistance in its own study.
- The honest catch: 40–48% of AI-generated code has been found to contain security vulnerabilities, and a rigorous trial found experienced developers were 19% slower with early-2025 AI tools.
- Main risks founders cite: scalability, vendor lock-in, customization ceilings, and security, explored honestly below.
The State of the Market (Why This Matters Now)
Let’s start with the number everyone quotes. The global low-code development platform market was valued at roughly $37.4 billion in 2025 and is projected to reach $264.4 billion by 2032, growing at a 32.2% compound annual rate.
The bigger story isn’t the dollar figure, it’s the adoption curve. Gartner has repeatedly forecast that 70% of new applications built by organizations would use low-code or no-code technology by 2025, up from less than 25% in 2020, and that this rises to roughly 75% by 2026. That’s one of the fastest enterprise-technology adoption curves on record.
Two more shifts matter for you specifically. Gartner also projects that citizen developers will outnumber professional developers by roughly 4 to 1 at large enterprises, and that about half of all new low-code customers now come from business buyers outside the IT department.
What this means for you: these aren’t fringe tools anymore. The low-code/no-code development has become the default starting point for a large share of new software, which means the operators in your industry are very likely already using them. The question is no longer “is this legitimate?” It’s “where does it fit, and where does it break?”
What Exactly Is the Difference? (No-Code vs. Low-Code vs. Vibe Coding)
These three terms get lumped together constantly, and the differences genuinely matter, in 2026 there are now three approaches in play, not two.
Approach What it is Who it’s for Examples No-Code Zero programming. Pure visual, drag-and-drop. Non-technical founders, solopreneurs, ops teams Bubble, Webflow, Adalo, Glide, Airtable Low-Code Visual-first, but you can drop in custom code. Small dev teams, technical operators Retool, OutSystems, Mendix, WeWeb, Microsoft Power Platform Vibe Coding You describe what you want in plain English; AI writes the actual code. Anyone — but genuinely risky without technical oversight Cursor, Lovable, Bolt, Replit That third row is the 2025–2026 wildcard. The term “vibe coding” was coined by Andrej Karpathy, former Tesla AI director and OpenAI founding engineer, in a February 2025 post on X, describing a way of building where you “fully give in to the vibes, and forget that the code even exists.” It caught on so fast that Collins Dictionary named it Word of the Year for 2025.
The honest one-line summary, which we’ll spend the rest of this article backing up with data: no-code is the fastest to start but hits walls earliest; low-code scales further but needs someone technical; vibe coding is incredibly fast and produces real, portable code, but carries security and maintainability risks that are very well documented by now.The Real Cost Comparison
This is where founders most need a straight answer. Treat these as planning ranges, not quotes, real costs depend on complexity, region, and how much you change your mind mid-build.
Build type Simple app Medium complexity Complex / enterprise Custom development (US/UK) $40K–$80K $80K–$200K $200K–$1M+ Custom development (offshore) $10K–$30K $30K–$80K $80K–$300K No-code platform (DIY) $500–$3K/yr $3K–$12K/yr $12K–$50K/yr No-code agency build $4K–$15K $15K–$50K $50K–$150K Low-code (enterprise tier) $20K–$75K $75K–$250K $250K–$1M+ At the validation stage, the cost case for no-code is hard to argue with, and the reason isn’t just the build price, it’s what you don’t spend. Tara Reed built her art-recommendation startup Kollecto on Bubble with no code at all, and reported keeping operational costs under $600/month for the first six months while validating the idea, eventually generating around $30K in early revenue and getting into 500 Startups, all before writing a line of code. Marlow’s founder, Mary, reported launching her coaching platform on Bubble for roughly $79/month plus about $200/month in supporting tools like Zapier and Mailchimp.
The hidden-cost truth worth underlining: platform subscriptions compound: An app that costs $29/month at launch can cost $500+/month at scale once you hit workload-based pricing (Bubble) or per-seat pricing traps. The discipline that separates founders who win with no-code from those who get burned: model your three-year cost at 10x your current usage, not your month-one bill.What this means for you: for MVP validation and early traction, the math favors no-code decisively. The math changes at scale where custom software development usually pays off, and the entire point of reading a guide like this is to know that in advance so the change doesn’t ambush you.Speed, Productivity & ROI: And the Honest Counterpoint
The speed numbers are real and they’re the strongest argument for these tools:
- Low-code/no-code can reduce development time by up to 90%.
- In GitHub’s own study of ~4,800 developers, those using Copilot completed tasks 55% faster.
- A Forrester Total Economic Impact study commissioned by Microsoft modeled a 206% ROI over three years for a composite organization using Power Apps (a later, broader Power Platform TEI modeled 224%).
There’s an important counterpoint, though, because faster feels and faster is not always the same thing. In a rigorous randomized controlled trial by METR, 16 experienced open-source developers worked through 246 real tasks. They predicted AI tools would make them 24% faster. They believed afterward they’d been about 20% faster. In reality, they were 19% slower when allowed to use early-2025 AI tools, METR has since said it’s re-running the study on newer tools.
Two honest readings of that, taken together: the productivity gains are most reliable for simple, repetitive, well-scoped work (the exact sweet spot these tools were built for), and the “speed” of AI-assisted building can be partly perceptual, real on greenfield prototypes, much shakier on mature, complex systems.
What this means for you: if you have limited runway, three months to a launchable MVP versus nine is the difference between finding product-market fit and running out of cash. That’s a genuine reason to start fast. Just don’t assume the same speed multiplier holds once your product is real, complex, and carrying users.Adoption by Industry: Is Your Sector Already Using It?
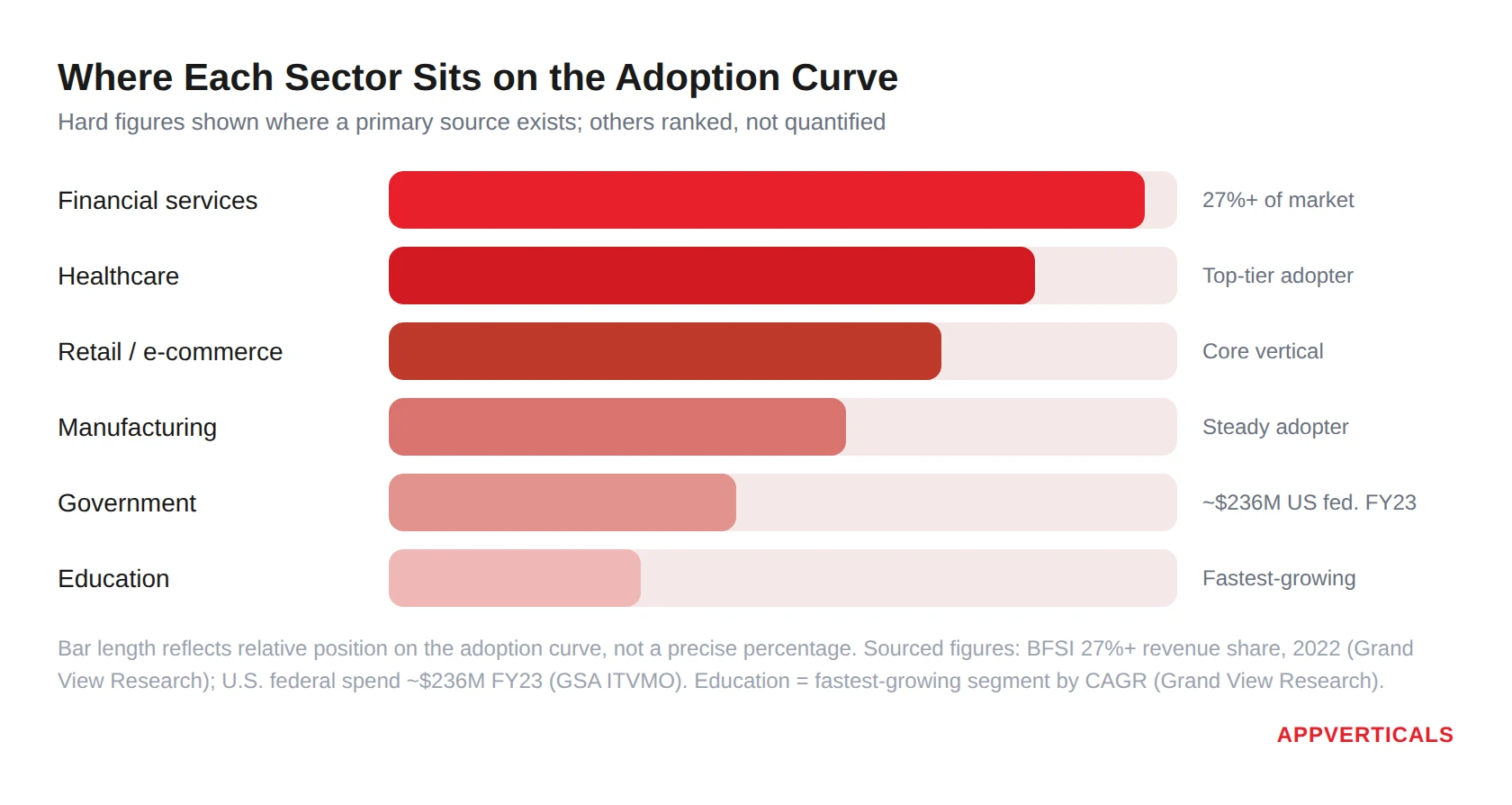
Adoption is uneven, and knowing where your sector sits tells you how much validation, and how many ready-made integrations and templates, already exist around you. The reliable signal here isn’t a precise “X% of your industry uses it” number (those float around a lot and rarely trace to a real source); it’s which sectors the analyst firms and the actual spending data consistently put at the front of the line. On that, the sources agree.
Grand View Research found that banking, financial services, and insurance (BFSI) was the single largest slice of the low-code market with over 27% of revenue in 2022, driven by client onboarding, back-office automation, and self-service tools.
MarketsandMarkets independently reaches the same conclusion: BFSI is the heaviest user and is projected to grow at the fastest rate, because these firms generate enormous volumes of data and constantly ship new products.
Here’s how the sectors line up, with what each is actually using these tools for:
Sector What the evidence shows Financial services (BFSI) The largest market segment, 27% of low-code revenue in 2022, and forecast to grow fastest. Used for client onboarding, loan origination, KYC, and customer portals. Healthcare Consistently ranked a top adopter; one health system reported building 80 clinical use cases in 12 months on low-code. Common uses include scheduling, reporting dashboards, and patient-intake forms within HIPAA constraints. Retail / e-commerce A core vertical across analyst segmentation; used for storefronts, inventory, point-of-sale, and marketing automation. Manufacturing A consistently named adopter, using low-code for process automation, quality-control apps, and IoT/operations dashboards. Government / public sector Slower adoption due to procurement and security rules, but growing: U.S. federal low-code/no-code spend reached ~$236M in FY2023 and has roughly doubled in four years. The Department of Defense alone accounted for ~$76M. Education Smaller today but one of the fastest-growing segments by CAGR (24%+). Emerging as a key vertical for low-code adoption in administration, learning tools, and student management systems. The Honest Risks with Low-Code/No-Code Development (What Nobody Tells You)
None of what follows is an argument against no-code, it’s the set of things to plan around so you use it deliberately instead of blindly.
Risk Who it affects most How to de-risk Scalability Consumer apps expecting fast user growth Load-test early at 10x your current usage; know your ceiling before users find it. Vendor lock-in Long-term products on a single platform Favor platforms that export clean code; write down an exit plan before committing. Pricing Apps with per-user or workload-based fees at scale Model the 3-year cost at 10x users, not the month-one bill. Customization ceiling Products where the software is the advantage If your edge is in the software, plan to move core logic to custom code eventually. Security Anything handling payments, health, or personal data Verify SOC 2 / HIPAA / GDPR before building; have an engineer review before launch. Risk 1: Scalability
No-code apps can slow noticeably at scale, and the manual processes propping up an MVP are often what break first. Kollecto is the textbook case: Tara Reed wrote that the model “began to fall apart” at around 1,500 monthly active users, not because Bubble itself collapsed, but because the human-in-the-loop steps behind it couldn’t scale.
Load-test early; find your ceiling before your users do.
Risk 2: Vendor lock-in
Rebuilding a maturing no-code app on custom infrastructure is a real, budgeted project, not a quick weekend fix. Platforms that export clean code (Webflow and others) reduce this risk; platforms that don’t, increase it.
Before you commit, model the worst case: what’s your exit plan if this platform doubles its price or shuts down in three years?
Risk 3: The pricing trap
Per-user pricing is fine for an internal tool and potentially catastrophic for a consumer app at scale; workload-based pricing can balloon unpredictably. Model costs at 10x your current users before choosing a platform.
Risk 4: Customization ceilings
If your competitive advantage is the software, a novel algorithm, a real-time system, deep custom logic, you will likely outgrow no-code eventually. If the software merely supports your business (a booking tool for a service company, an internal dashboard), no-code is usually enough indefinitely.
Risk 5: Security (the 2026 headline risk)
This is where vibe coding has produced well-documented failures:
- In a May 2025 study, 170 of 1,645 sampled Lovable-built apps (about 1 in 10) were leaking user data through the same class of misconfiguration, missing database row-level security, later assigned.
- An October 2025 scan by Escape.tech of ~5,600 vibe-coded apps found over 2,000 high-impact vulnerabilities, 400+ exposed secrets (API keys, tokens), and 175 instances of exposed personal data.
- One documented case, Moltbook, exposed roughly 1.5 million API keys due to missing row-level security; a separate February 2026 Lovable-built EdTech app exposed roughly 18,000 users, including thousands of student accounts.
- Across studies, roughly 40–48% of AI-generated code has been found to contain security flaws.
No-code and low-code platforms also vary enormously in formal compliance (SOC 2, HIPAA, GDPR). Therefore, it is important to verify the platform’s compliance posture before you build a single screen that touches sensitive data.
WHAT THE EXPERTS SAY: Tim Buckley, RFID executive with 15+ years in the field, on whether compliance kills low-code: he reported “no issues with DoD and government protocols so far” with their no-code/low-code stack, citing single sign-on, multi-factor authentication, and audit logging, with controls built so that formal certification is “an audit rather than a re-architecture.”The takeaway for founders: compliance is achievable on these platforms, if you choose and configure them deliberately. The failures above were almost all misconfiguration, not platform impossibility.
Real-World Proof: What Has Actually Been Built
Serious businesses build this way every day. A few concrete, sourced examples:
Kollecto by Tara Reed: non-technical founder, built the MVP and the art-matching logic on Bubble; ~$30K early revenue, into 500 Startups, all no-code, and then hit a scaling wall around 1,500 MAU.
Teal by David Fano: the “digital career companion” raised $5 million (investors including Flybridge) while building on a no-code stack with Bubble, specifically so the whole team, not just engineers, could iterate on the product.
Marlow by Mary Fox: built on Bubble for ~$79/month, pivoted from direct-to-consumer to organizational coaching based on user feedback after roughly 10 iteration cycles, proving the “narrow scope, quick launch, real users, then iterate” playbook.
Y Combinator, Winter 2025: YC CEO Garry Tan revealed that for about 25% of the batch, ~95% of the code was AI-generated. Crucial nuance YC stressed: these were highly technical founders who chose AI, not non-technical people outsourcing to a black box, and ~80% of the batch were building AI products.
What this means for you: the question stopped being whether serious businesses build this way. It’s whether it fits your business model, timeline, and complexity, and what your migration plan is when it works.
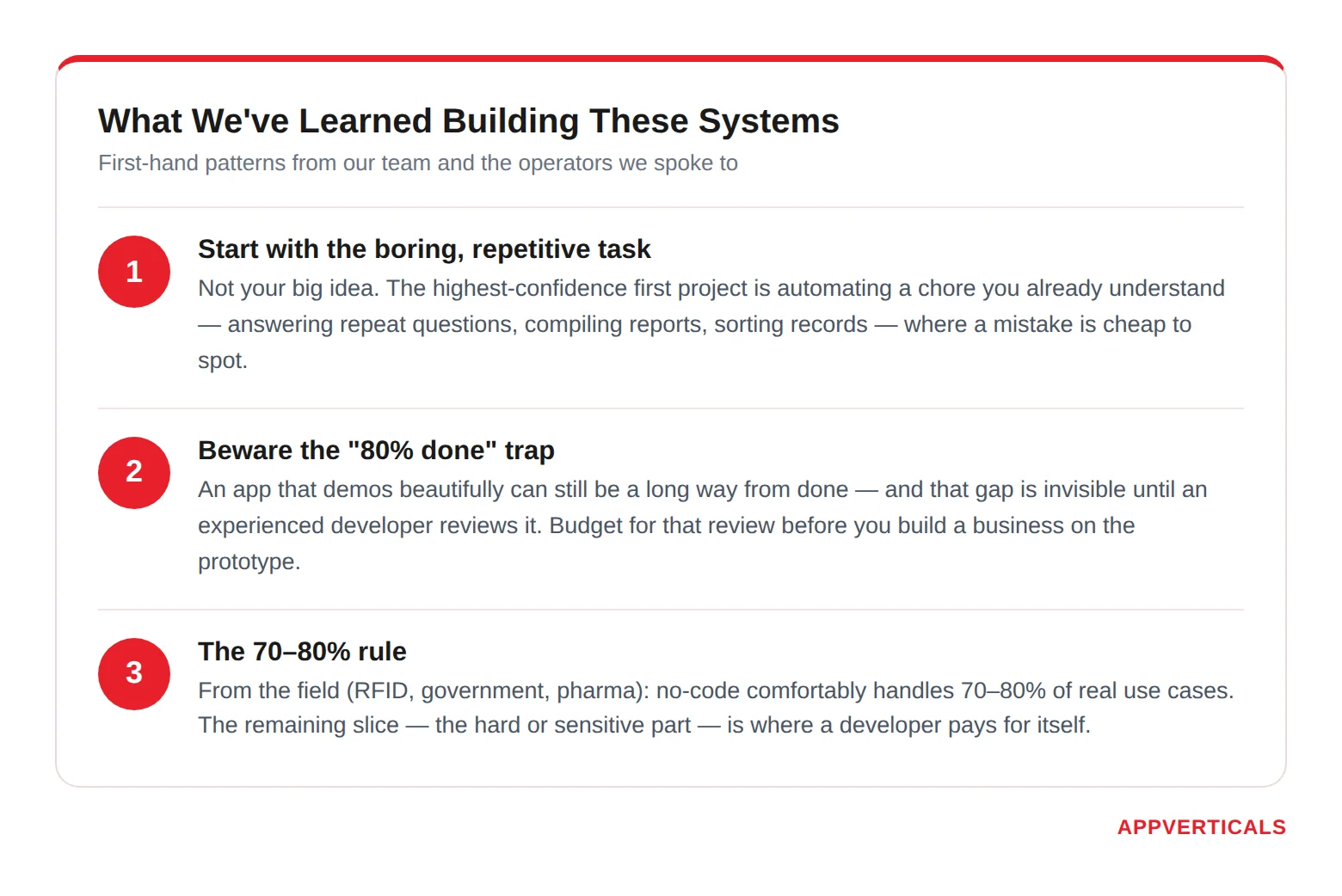
What We’ve Learned Building These Systems Firsthand
Here’s what actually plays out when founders and business owners bring these tools to us, patterns you can apply before you spend anything.
- The best first project is almost never your big idea, it’s the boring, repetitive task eating your team’s time. Our team has built several internal systems using low-code and no-code tools, and the lesson lines up exactly with the market data: these tools pay off most when they automate repetitive work, not when they try to be your flagship product. A few of the things we’ve automated this way:
- An internal help assistant that answers staff questions instantly by pulling from our own documentation, so people stop interrupting each other for the same answers, and we can see which documents are missing or unclear.
- A financial summary tool that gathers spending and expense data on a schedule and emails leadership a plain-English read on profit, burn rate, and where the money is going, work that used to mean someone manually assembling a spreadsheet.
- An intake-and-sorting system that automatically captures incoming records and files them into the right place, so nothing gets lost and no one has to sort entries by hand.
Notice what these have in common: none is a product we sell. They’re internal chores, answering repeat questions, compiling reports, sorting records that used to swallow hours. If you’re a founder or business owner, this is the highest-confidence place to start: point these tools at a repetitive task you already understand, where a mistake is cheap and easy to spot. That’s the use case the adoption data rewards, and it’s where you’ll feel the value fastest.
- The “80% done” trap, the most expensive misunderstanding we see. This one is worth slowing down on, because it costs founders real money and time. A pattern we run into often: someone arrives with an app they built (or had built) using a no-code tool or AI “vibe coding,” convinced it’s about 80% finished and just needs us to “wrap it up.”
When our team looks under the hood, the work is disorganized and hard to follow, and the genuinely time-consuming part is the review needed before anyone can safely build on top of it. Founders are understandably frustrated: the app looks finished, so it’s fair to ask why it isn’t.
Here’s the honest version, and the thing to internalize before you start: an app that demos beautifully can still be a long way from done, and that gap is mostly invisible until an experienced developer inspects it. It’s the same reason the security failures we discussed earlier kept slipping through: everything works in the obvious path, and the problems only show up when someone goes looking.
If you build a prototype this way (a smart move for testing an idea), budget time and money for a proper review before you treat it as the foundation of a real business. Plan for that step and it’s a minor line item; discover it after launch and it’s a crisis.
- From the field: even serious, regulated industries are using these tools, selectively. We also spoke with Tim Buckley, an executive with 15+ years in RFID (the tracking technology behind things like cold-chain and pharmaceutical logistics), about where these tools fit in demanding, hardware-heavy enterprise work. A few things he told us that should reassure, and guide, a cautious founder:
Customers rarely ask for low-code by name. As he put it, “it is typically something we present as a viable solution to save costs”, and more clients are warming to it as awareness grows.
On where the line sits, he was specific: “no-code applications will adequately handle 70–80% of the RFID use cases across all verticals,” with only the most demanding, high-volume, complex projects needing fully custom development.
His team deliberately runs a hybrid setup, their own proven tools handling the specialized parts, combined with no-code platforms for the rest, because, in his words, “an important part is knowing how the system works.”
And on compliance, which scares off a lot of founders in regulated spaces, he reported “no issues with DoD and government protocols so far,” with the right security controls (single sign-on, multi-factor authentication, audit logging) and certification treated as a checkbox rather than a rebuild.
That 70–80% figure, coming from someone deploying this in security-sensitive government and pharma settings, is the most useful rule of thumb: these tools comfortably handle the majority of what most businesses need, and the remaining slice, the genuinely hard or sensitive part, is where bringing in a developer pays for itself.
The 2026 Wildcard: Vibe Coding and What It Actually Changes
Vibe coding is recent enough that a lot of advice predates it entirely. Here’s the current picture for any founder trying to make sense of the term:
The term went from a February 2025 tweet to Collins’ Word of the Year in nine months.
AI coding adoption is near-universal among developers: 84% use or plan to use AI tools (Stack Overflow 2025), and 51% use them daily.
GitHub reports its Copilot assistant now generates ~46% of the code written by developers using it, and Gartner projects AI will generate ~60% of all code by the end of the period.
The honest take for founders: Vibe coding gives you no-code-like speed but outputs actual code, so you avoid platform lock-in. That’s its real advantage over no-code. But the security risk is not theoretical (see the Lovable, Moltbook, and Escape.tech data above), and the METR trial shows AI doesn’t reliably speed up experienced developers on complex, mature work.The emerging smart path is hybrid: no-code or vibe coding for the front-end MVP, then custom development for the backend and security-critical components when it matters. This is essentially what YC’s “highly technical founders using AI” are doing, and what Tim Buckley described doing with RFID.
Bottom line: vibe coding isn’t replacing no-code or custom development, it’s a third option sitting alongside them, strongest in technical hands and dangerous in unprepared ones.
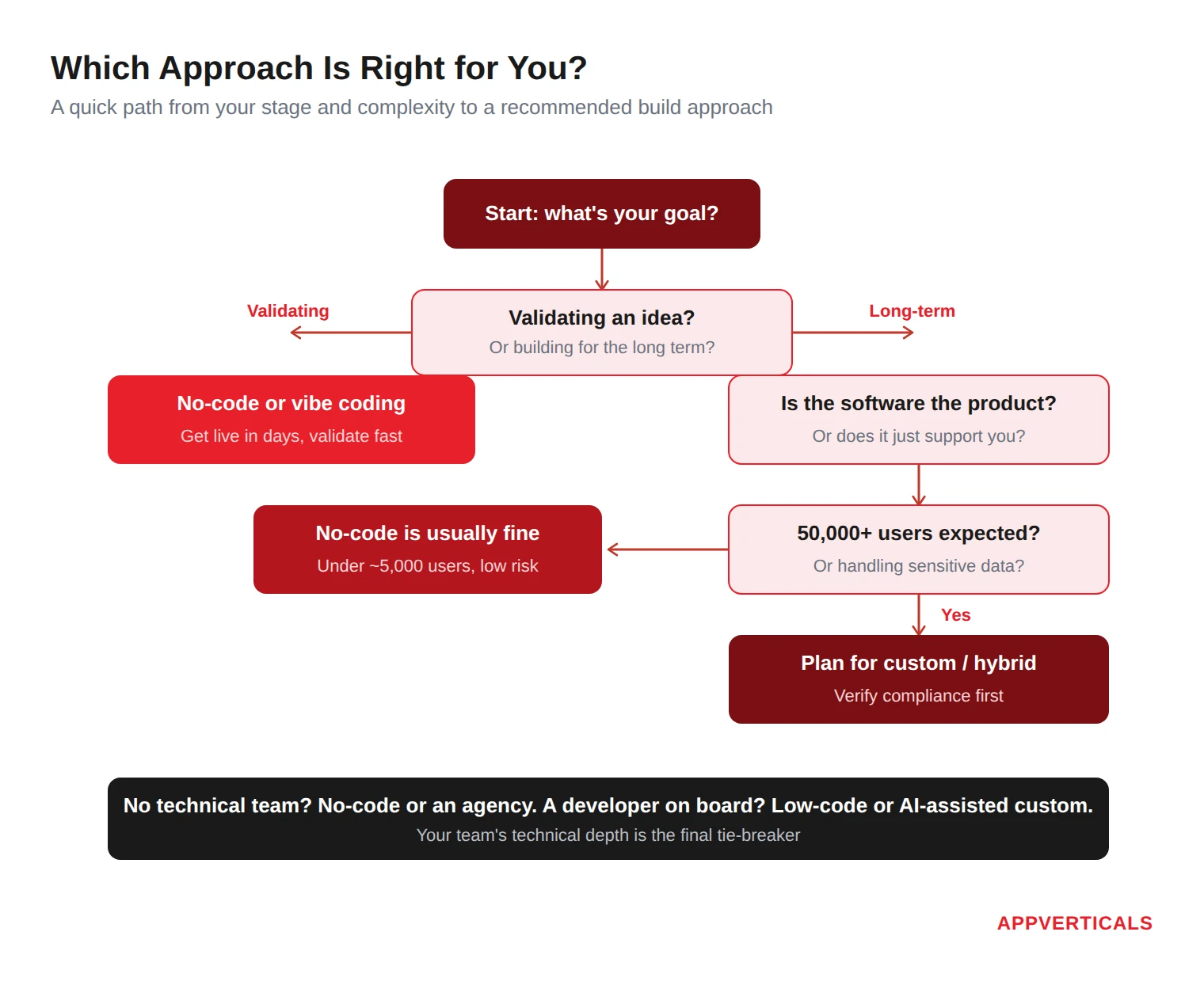
The Decision Framework: Which Approach Is Right for You?
Five questions. Answer them honestly and you’ll know which category to explore.
- Are you validating an idea, or building a long-term product?
- Validating → no-code or vibe coding; get live in days.
- Long-term → think hard about scale before committing to any one platform.
- Is your competitive advantage in the software, or supported by it?
- Supported by it (a booking app for your service business) → no-code is usually fine, possibly forever.
- The software is the product (a novel algorithm, real-time engine) → you’ll likely need custom code eventually.
- How many users do you expect in Year 2?
- Under ~5,000 → no-code handles most use cases.
- ~5,000–50,000 → low-code or hybrid; test performance early.
- 50,000+ → plan a migration path; no-code may become a ceiling.
- Do you handle sensitive data (payments, health, legal, financial)?
- Yes → verify SOC 2 / HIPAA / GDPR compliance before building anything.
- No → standard platform security is usually sufficient.
- Do you have technical resources on your team?
- None → no-code or a no-code agency (avoid low-code; it needs maintenance).
- Some → low-code or vibe coding with oversight.
- A developer on the team → low-code or AI-assisted custom development (the 2026 optimal).
This framework tells you which category fits.
Choosing the right platform, or knowing when to bring in engineers to review a vibe-coded build before it reaches users, is the next decision.
Conclusion
The market trajectory is not ambiguous: low-code, no-code, and now AI-assisted “vibe” development are all growing fast and are already the default starting point for a large share of new software. But the right tool depends entirely on your stage, your complexity, and your goals.
The smartest founders in 2026 aren’t arguing “no-code vs. custom.” They’re asking two sharper questions: What’s the fastest, cheapest way to validate this idea? And what’s my migration plan when it works? Get those two right, plan for the ceilings before you hit them, and the statistics in this article stop being background noise and start working as a map.
Month: June 2026
Agentic AI for Businesses: What It Is, What It Does, and Whether Your Business Is Ready

Most businesses think agentic AI is a smarter chatbot. One that can send emails, pull reports, maybe schedule a meeting. That framing is what’s causing most deployments to underdeliver, or collapse entirely. Agentic AI is a class of autonomous AI systems that can perceive a business environment, reason toward a goal, and take multi-step action, across tools, systems, and workflows, without a human managing each step.
It doesn’t wait for instructions. It doesn’t stop at generating a response. It works through an entire process on its own, identifying what needs to happen, calling the right tools, making decisions along the way, and adapting when conditions change. That’s a fundamentally different category of system, not a chatbot upgrade.
By 2026, 40% of enterprise applications are projected to include task-specific AI agents, reports Gartner. Companies deploying agentic AI expect an average ROI of 171%, roughly three times the return of traditional automation. And yet fewer than 10% of organizations have deployed it at scale, while Gartner forecasts that 40% of agentic AI projects will be canceled by 2027.
That gap isn’t a technology problem. It starts with how businesses frame what they’re building. This guide serves that exact gap, aimed at helping you understand what agentic AI is, what it can do and whether your business is ready for it or not.
What Is Agentic AI? (And How Is It Different From a Chatbot or RPA?)
The easiest way to understand agentic AI is to understand what it replaced, and why those previous tools kept hitting a ceiling.
Chatbots respond. Robotic process automation (RPA) repeats. Agentic AI reasons.
An AI chatbot is essentially a very sophisticated question-answering machine. It takes an input, processes it through a language model (LLM), and produces an output. That’s the end of its job. If you want it to do the next thing, you have to ask again.
RPA goes a step further, it can execute a sequence of steps, but only the exact steps it was programmed to follow. Change the form layout, rename a field, or add an exception to the process, and the bot breaks. IT teams who’ve managed RPA at scale know this maintenance burden intimately.
Agentic AI, a product of latest advances in AI development, handles ambiguity. It can interpret a goal, choose the right sequence of actions, use external tools (APIs, databases, and search), adjust its approach mid-process, and recover from partial failures. Think of it as the difference between handing someone a script and hiring someone who understands the objective.
Here’s how the three compare side by side:
| Aspect | Traditional Automation / RPA | Chatbot (Generative AI) | Agentic AI |
|---|---|---|---|
| Input type | Structured data, fixed triggers | Natural language prompt | Goal, instruction, or event |
| Output type | Predefined action or report | Text response | Completed multi-step workflow |
| Decision-making | Rule-based, no deviation | Per-prompt, no memory | Goal-oriented, adaptive across steps |
| Human role | Sets up rules upfront | Prompts each interaction | Sets goal; reviews outcomes with approval gates for higher-stakes decisions |
| Best for | Repetitive, stable, rule-bound tasks | Single-turn Q&A, content generation | Cross-system processes requiring judgment |
There are a few terms that come up constantly in agentic AI conversations and are worth knowing as someone who’s interested to invest in the technology:
- Multi-agent systems: Multiple AI agents working in coordination, each handling a specialized part of a larger workflow. One agent gathers data, another analyzes it, another triggers an action.
- Human-in-the-loop: A design pattern where certain decisions or thresholds require human approval before the agent proceeds. Not a limitation, it’s how most responsible deployments are structured.
- Tool use: The agent’s ability to call external services, send an email, query a database, and update a CRM record, as part of completing a task.
A joint MIT Sloan Management Review and BCG survey from spring 2025 found that 35% of organizations had already adopted agentic AI, with another 44% planning near-term deployment.
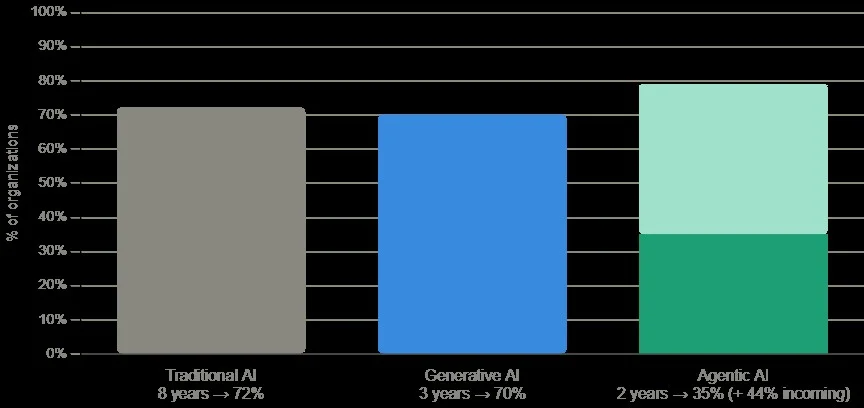
Data: MIT Sloan Management Review & BCG
Every previous wave of enterprise technology followed the same pattern: slow start, gradual adoption, eventual plateau. Agentic AI isn’t following that pattern. Traditional AI took eight years to reach 72% adoption. Generative AI hit 70% in three. Agentic AI is already at 35%, in under two years, with another 44% of organizations planning deployment soon. The technology is spreading faster than most companies have built a strategy to manage it.
What Agentic AI Actually Does Inside a Business
When a client says they want agentic AI, the first question we ask is: “What business outcome are you trying to achieve?” Not which use case looks impressive in a demo? Not which workflow has the most automation potential on paper but what is the actual business problem that you are trying to solve with AI, says Faique Ali, Lead AI Engineer at AppVerticals.
The answer almost always changes the conversation. Most teams arrive with a solution already in mind, usually because they’ve seen a competitor announce something, read a case study, or sat through a vendor demo. The starting point is the technology, not the problem it’s meant to solve.
As Faique puts it: “Clients often come asking for a complex AI solution when a much simpler workflow automation can solve most of the problem.”
“We want agentic AI” usually turns out to mean faster support resolution, cleaner lead handoffs, or less manual data entry. So the real first question isn’t which agent to build, it’s whether you need an agent at all.
That said, when the use case does warrant one, the pattern is consistent: agents deliver most where a person is currently acting as glue between systems. This is also why agentic AI projects often overlap with custom software development. The agent itself is only one piece of the solution; it still needs to connect with CRMs, ERPs, databases, communication platforms, and internal workflows. In practice, the biggest gains usually come from designing software and integrations around the agent, not from the model alone.
Think about what happens when a new enterprise customer signs a contract. Someone from sales closes the deal. Then someone manually updates the CRM. Then someone emails finance to set up billing. Then someone pings the onboarding team. Then someone creates a project in the PM tool. That chain of handoffs, each one a person translating information from one system into another, is exactly what an agent is built for.
The scale of the problem is well-documented. Asana’s Anatomy of Work report found that employees spend roughly 60% of their working hours on “work about work”, status updates, switching between tools, tracking down information, and coordinating handoffs, leaving only 40% for the skilled work they were actually hired to do. That ratio hasn’t improved as companies have added more tools; in most cases, it’s gotten worse. The AI automation ROI data makes a compelling case for why this is exactly the problem agentic AI is built to close.
Before deploying any agent, it’s worth running your candidate use cases through what we call the Four Traits of a High-Fit Use Case, discussed below.
The Four Traits of a High-Fit Agentic AI Use Case
A use case is genuinely agent-ready when it has all four of the following:
- ✓
A repetitive process with clear rules: not every edge case, but a definable core that runs on policy - ✓
Cross-system dependencies: the task requires pulling from or pushing to more than one tool - ✓
A measurable outcome: you can track whether the agent succeeded (resolution rate, time saved, error rate) - ✓
A human currently acting as connective tissue: someone whose job is largely to move information between systems
If a use case doesn’t have all four, it’s either too simple for an agent (use basic automation) or too ambiguous to deploy reliably (reduce scope first).
In practice, the highest-impact applications tend to cluster around a handful of business functions:
IT Service Management
An employee submits a ticket. The agent reads it, checks the knowledge base, queries the user’s permissions, cross-references past similar issues, and either resolves it automatically or routes it to the right tier with full context already assembled. No human triaging a queue at 2am.
Employee Onboarding
When a new hire’s start date is confirmed, an agent triggers the full onboarding sequence, provisioning accounts, scheduling orientation, sending policy documents, notifying the payroll team, creating their tools access. What used to take a week of back-and-forth coordination runs in hours.
Finance and Contract Processing
Invoice arrives. Agent reads it, matches it against the PO, flags discrepancies, routes for approval if thresholds are met, and updates the ledger. Or doesn’t flag anything and just processes it, because it matched perfectly.
Lead Qualification
Inbound leads get scored against firmographic criteria, enriched with data from third-party sources, cross-referenced against CRM history, and routed to the right sales rep, with a briefing already assembled, before anyone manually picks up the thread. It’s one of the cleaner examples of what SaaS platform development built around agentic workflows actually looks like in practice.
Gartner projects that by 2028, 33% of enterprise software applications will include agentic AI, enabling 15% of autonomous day-to-day business decisions. That’s not a fringe use case, that’s core operations.
Where Businesses Are Seeing the Most ROI from Agentic AI
The ROI numbers get attention. But it’s worth looking at where those returns are actually coming from, because the pattern is more instructive than the headline stats.
Companies deploying agentic AI systems are expecting an average ROI of 171%, and for US enterprises specifically, that number climbs to 192%, roughly three times the return of traditional automation. IBM’s EMEA survey 2025 found that 92% of business leaders expect measurable ROI from agentic AI within two years.
The companies generating the biggest returns aren’t using agents everywhere. They identified narrow, high-volume workflows where the cost of human coordination was measurable and the process was documentable. A few production examples from public reporting:
JPMorgan has over 400 AI use cases running in production daily, not as experiments, but as operational infrastructure. Their legal and compliance teams have seen some of the sharpest efficiency gains.
Salesforce’s legal teams using purpose-built AI report a 14% reduction in outside counsel spend, roughly $252K annually for median-sized legal departments.
These aren’t outliers. They’re early movers who figured out the same thing: the ROI comes from specificity, not from deploying broadly.
Rylko Roman, who leads enterprise engineering at a SaaS-scale organization, captured the diagnostic mindset well after a year of production deployments: “We learned to ask a simple question of every agent: What decision do you accelerate? If the answer is ‘answering a chat,’ we’re not ready. If the answer is ‘assemble evidence across logs, tickets, and dashboards so an on-call can act in seconds,’ that’s a candidate.”
That question, what decision does this agent accelerate? is a more useful filter than any vendor checklist.
The ROI potential is real, but so is the distance between a promising pilot and a production system that actually delivers it. Understanding what separates the two is where most teams underinvest.
Why Most Agentic AI Projects Stall Before They Scale
The gap between ambition and execution is well-documented. According to Deloitte’s 2025 Emerging Technology Trends study, while 30% of organizations are exploring agentic AI and 38% are piloting it, only 14% have solutions ready to deploy, and just 11% are actively running them in production.
MuleSoft’s 2025 Connectivity Benchmark Report, drawn from 1,050 enterprise IT leaders, found that 93% have implemented or plan to implement AI agents within two years. And Gartner predicts that over 40% of agentic AI projects will be canceled by end of 2027, citing escalating costs, unclear business value, and inadequate risk controls.
That’s a significant delta between intent and execution. The projects that stall aren’t failing because the technology doesn’t work. They’re failing for reasons that show up early, and that experienced teams learn to spot quickly.
The Five Most Common Reasons Agentic AI Pilots Fail
Poor data infrastructure
Agents don’t create data quality problems; they expose and amplify existing ones. If your customer records are fragmented, your agent will make fragmented decisions, at scale, faster than any human would. Before an agent goes live, the data it depends on needs to be clean, accessible, and owned.
Deloitte found that nearly half of organizations cite searchability and reusability of data as their top barriers to AI automation, this isn’t a minor friction point, and it’s a deployment wall.
Use case too broad to measure
“Improve customer service” is a goal. “Reduce first-contact resolution time by 30% for Tier 1 IT tickets” is a use case. The difference determines whether you can evaluate the agent, improve it, or justify continuing.
Pilots that start with vague mandates rarely make it to production.
No governance design
Who decides what the agent is allowed to do on its own? What requires a human sign-off? What happens when it makes a mistake? These aren’t edge cases, they’re deployment decisions.
Organizations that skip governance design in favor of shipping faster spend the back half of the project rebuilding trust with the teams the agent is supposed to help.
Integration complexity underestimated
There is no truly off-the-shelf agent that plugs into your existing stack and just works. Every organization’s combination of ERP, CRM, ITSM, and communication tools is different. Custom integration work is real, it takes time, and it’s often underplanned in initial budgets.
MuleSoft’s 2025 research found that only 29% of applications within enterprises are typically connected, meaning most agents are flying partially blind from day one.
No one owns the failure
As Faique Ali puts it: “Teams build impressive demos, but no one is comfortable letting it run in production, because there are no clear boundaries for what the AI can and cannot do.”
If responsibility for the agent’s decisions, approvals, and error handling isn’t assigned before launch, the system stays stuck in prototype mode. Agentic AI only works when someone is accountable for what it does.
The data infrastructure point is where we see the most expensive surprises. Teams pick a use case, start development, and three weeks in discover that the data the agent depends on lives in five different places, has no consistent schema, and hasn’t been maintained properly in years. That’s not a blocker you can engineer around on a tight timeline, it’s a project reset. The conversations about data readiness need to happen before the first sprint, not during it.
Faique frames the prerequisite bluntly: “Agentic AI doesn’t fix unclear processes, it amplifies them.” The businesses that succeed aren’t necessarily the ones with the most advanced AI stack. They’re the ones that already understand their own operations well enough to automate them safely.
Gib Bassett, writing on Medium about the context gap in enterprise AI deployments, puts it plainly: “Here’s what every working agentic AI system has in common, and what every failed one is missing: a human who can validate the agent’s outputs, challenge its assumptions when they drift, and correct course when the world changes faster than the model.”
The working knowledge behind how analysts actually use data, the caveats, dependencies, stakeholder expectations, is often invisible to the leaders most eager to automate it. That’s why the diagnostic conversation matters more than the build conversation, at least in the first thirty days.
Not ready to build yet? Start with readiness. Most agentic AI projects don’t fail on technology, they fail on organizational preparation. This guide on How to Prepare Your Organization for AI Adoption walks through the data, governance, and workforce groundwork that has to be in place first.
Is Your Business Ready for Agentic AI? The AppVerticals Stage-by-Stage Framework
The question isn’t whether agentic AI works. It does, with the right conditions. The more useful question is: what does “ready” actually look like for a company at your stage?
This framework came out of something we kept running into with clients. A 25-person startup and a 5,000-person enterprise are not making the same decision. They have different data maturity, different integration complexity, different governance requirements, and very different risk tolerance for a failed pilot. And yet most of the advice circulating about agentic AI readiness treats them identically.
So we did what we typically do before we formalize any guidance: we went back to the work. We reviewed our own deployment history across client engagements, ran structured conversations with stakeholders at multiple organizational stages, and stress-tested our assumptions against the failure patterns we were seeing in the market.
What came out of that process wasn’t a single checklist. It was a recognition that readiness is stage-dependent, and that the questions a startup needs to answer before deploying an agent are fundamentally different from the ones an enterprise needs to answer.
The framework below reflects that. It’s what we use internally when a client asks us where to start, and it’s what we walk prospective clients through before any scoping conversation begins.
| Decision Area | Startup (<50 people) | Growth-stage (50–300 people) | Enterprise (300+ people) |
|---|---|---|---|
| Where to start | Single high-volume, low-risk workflow with a clear outcome: lead qualification, support triage, contract first-pass. Keep scope to one system integration. | Map where humans are acting as connective tissue between existing tools. Build a single cross-system agent in one department before expanding. | Identify the workflow with the highest coordination cost and the clearest governance path. Run a time-boxed pilot with defined success metrics before committing to broader rollout. |
| What to watch for | Data hygiene records are often informal at this stage. An agent running on inconsistent data produces inconsistent outputs. | Integration debt—growing companies accumulate tools fast. Understand your current stack before adding an orchestration layer on top. | Change management—agents change how people work. Enterprise adoption fails as often from internal resistance as from technical issues. |
| What to avoid | Deploying an agent as a substitute for a missing process. If the human workflow isn’t defined, the agent can’t automate it. | Trying to build everything in-house. The custom development requirement is real; the time cost without experience is higher than most teams anticipate. | Choosing use cases based on hype. The best agentic AI projects at enterprise scale solve a problem someone has been complaining about for three years, not one that surfaced in a strategy presentation. |
The pattern we see most consistently across all three stages: the organizations that get real value from agentic AI in year one are the ones that resist the urge to go wide. They pick one workflow, instrument it properly, demonstrate a measurable outcome, and expand from there. The ones that struggle usually tried to solve too much at once, and ended up with a pilot that couldn’t prove anything to anyone.
That’s not a technology problem. It’s a scoping problem. And it’s one that shows up regardless of company size, budget, or how sophisticated the underlying model is.
Helping teams get that scoping decision right, before the build starts, is where we spend most of our time with new clients. [Talk to our team →]
Final Thoughts
The businesses getting real value from agentic AI aren’t necessarily the ones with the largest budgets or most advanced tech stacks. They’re the ones that identified a specific workflow problem, somewhere a human was acting as the glue between systems, and deployed an agent to handle it end to end.
Lead AI Engineer at AppVerticals, Faique Ali puts it straight: “The most successful AI agents are not the ones doing everything. They’re the ones doing specific jobs exceptionally well.”
The technology works. The ROI data is real. The risk is also real, particularly for organizations that skip governance and data preparation in favor of getting something live fast.
The smartest first move is usually the narrowest one. A single workflow, fully instrumented, with a clear success metric and a governance plan in place before launch. That pilot becomes the proof of concept that earns the next one. And the one after that.
If you’re not sure where that starting point is for your specific operation, that’s exactly the kind of conversation worth having before you commit to a build.
Is Agentic AI the Right Next Move for Your Business?
We help companies identify, scope, and build AI agents that reach production, not just demos.
Explore Our AI App Development Services
Healthcare CRM Software: Features, Real Costs & How to Choose in 2026
A healthcare CRM is a purpose-built patient relationship management system designed to handle HIPAA-regulated data, integrate with EHR platforms, and automate the clinical and administrative workflows that generic CRM tools were never designed for. Pick the wrong one and you inherit either a compliance liability or a system that can’t talk to your EHR. The choice comes down to three variables: your integration requirements, your data ownership needs, and whether your patient workflows are standard enough for an off-the-shelf product or complex enough to justify a custom build.
Most healthcare organizations already know they need one. What they don’t know is what building one actually involves, and that gap is where projects go wrong. Timelines blow out because EHR sandbox access takes longer than anyone planned. Budgets collapsed because HIPAA architecture was scoped as an afterthought. And vendors get selected without anyone asking the one question that determines legal liability from day one.
Deborah Vick is the CEO of Vicktorious Academy and a chronic illness patient advocate who has navigated complex healthcare systems across nearly 40 years of personal experience with multiple chronic illnesses, both visible and invisible. Her perspective on where communication breaks down is direct:
Every patient I work with tells me the same thing: every time they see a new provider, they are starting from zero. Their history, their conditions, their preferences, none of it travels with them. That is not just frustrating. It is a risk.
That’s the problem a well-built healthcare CRM solves. This guide covers what it takes to build one properly.
TL;DR
- A healthcare CRM manages the relationship layer; communication history, follow-ups, referral tracking, while your EHR handles the clinical record. They’re complementary, not interchangeable.
- Generic CRMs (Salesforce, HubSpot) aren’t built for PHI. Retrofitting HIPAA compliance onto one almost always costs more than building right from the start.
- Before you sign any dev partner: ask if they’ll sign a Business Associate Agreement (BAA). If there’s hesitation, walk away, it’s a legal requirement, not a formality.
- Realistic build costs: MVP $40K–$80K · Mid-market $80K–$150K · Enterprise $150K–$300K+. The single biggest variable is EHR integration.
- EHR credentialing (Epic, Cerner) takes 6–12+ weeks before a line of integration code can be written. Any timeline that doesn’t account for this will slip.
- HIPAA compliance is a foundation, not a feature. Scoping it as a late-stage checklist is the #1 source of cost overruns.
- Budget 15–20% of your build cost annually for maintenance, security patches, and EHR API updates.
- Off-the-shelf SaaS works if you have fewer than 20 users and standard workflows. Custom makes sense when you need deep EHR interoperability, full data ownership, or a platform that scales with your org.
What Is Healthcare CRM Software, And How Is It Different from a Regular CRM?
The simplest way to explain it: an EHR tracks what happened clinically. A healthcare CRM tracks what happens relationally.
Your EHR stores diagnoses, prescriptions, lab results, and encounter notes. It’s a clinical record, built to support treatment decisions and regulatory documentation. A healthcare CRM manages a different layer entirely: who contacted the patient and when, whether they showed up to their follow-up, which referral source sent them, and how they’re engaging with their care plan between visits.
The two systems are complementary. They’re meant to talk to each other. But they’re not interchangeable, and confusing them is exactly how healthcare organizations end up building the wrong thing.
A regular CRM, Salesforce, HubSpot, Zoho, handles leads, deals, and contacts. That architecture simply doesn’t map to healthcare. There’s no concept of Protected Health Information (PHI) in a standard CRM schema. There’s no HIPAA audit log. Role-based access doesn’t account for clinical roles. And the moment a developer working on your CRM touches real patient data in a test environment, you’ve created HIPAA exposure that a standard software vendor agreement doesn’t cover.
A purpose-built healthcare CRM solves for all of this from the ground up, with a data model that treats patient identity, consent, and communication history as first-class objects, and with a compliance architecture that’s built in, not bolted on.
The distinction matters practically. Organizations that start with a generic CRM and try to ‘add HIPAA compliance’ later almost always discover the same thing: the architectural debt is too deep to fix incrementally. It’s cheaper, and faster, to build right from the start, which is exactly what purpose-built healthcare software development is designed to do.
EHR vs. Healthcare CRM: Key Differences
| Function | EHR (Electronic Health Record) | Healthcare CRM |
|---|---|---|
| Primary purpose | Store and manage clinical data | Manage patient relationships and communication |
| Data it holds | Diagnoses, prescriptions, lab results, encounter notes | Communication history, engagement records, referral sources, care plan adherence |
| Patient outreach | Limited: portal messages only | Multichannel: SMS, email, telephony, automated sequences |
| Analytics | Clinical outcomes and documentation metrics | Engagement rates, communication effectiveness, referral attribution |
| Regulatory requirement | HIPAA, ONC certification | HIPAA compliance (BAA required with vendor) |
Why Healthcare Organizations Are Prioritizing Custom CRM Right Now
The short answer is that off-the-shelf tools have hit a ceiling, and patients have started noticing.
Patient volumes are climbing. Chronic disease management requires more touchpoints than any manual workflow can sustain. Telehealth’s permanence has multiplied the number of communication channels healthcare organizations are expected to manage simultaneously.
But the deeper pressure is something Deborah Vick articulates from the patient side with precision. She has spent decades managing multiple chronic conditions across fragmented provider networks, and she describes the structural communication failure that no amount of portal technology has fully solved:
One of the biggest challenges is the lack of interoperability between healthcare systems. I currently receive care from specialists across multiple healthcare organizations. While some information is shared, critical clinical notes, provider observations, and treatment rationale are often missing. This means patients must repeatedly tell their stories, explain complex medical histories, and bridge communication gaps between providers. During hospitalizations or urgent medical situations, these gaps can delay care and create unnecessary confusion. — Deborah Vick, CEO, Vicktorious Academy
Referral leakage is a growing problem for hospital networks: patients referred to a specialist and never followed up represent both a care gap and lost revenue. Automated referral tracking, a core CRM function, can recover significant volume that simply disappears in organizations still running on spreadsheets and manual follow-up calls.
The practices and health systems investing in CRM infrastructure are recognizing something straightforward: the relationship layer of healthcare has always existed. What’s changed is that patients now have enough options to punish organizations that manage it poorly.
Vick also illustrates what effective healthcare communication actually looks like in practice, and what makes it possible sharing her perosnal experience:
“Today I had a severe myasthenia gravis episode. I was able to reach my concierge medicine office via their phone and answering service. The on-call doctor called me back, looked at my medical chart, and I could give him information about what was in my chart because I was also showing symptoms of a UTI. Through our conversation, he was able to look up past conversations with the doctors to see where we were at and what I needed. He ordered me antibiotics without me having to go to the hospital. Being able to communicate with an on-call doctor was essential.”
That kind of interaction, a provider who can pull communication history, review the chart, and make a real-time clinical decision without an in-person visit, is exactly what a well-integrated healthcare CRM infrastructure makes possible at scale.
The practices and health systems investing in CRM infrastructure are recognizing something straightforward: the relationship layer of healthcare has always existed. What’s changed is that patients now have enough options to punish organizations that manage it poorly. The broader forces driving this shift, value-based care, AI-assisted workflows, interoperability mandates, are covered in depth in our healthcare software development trends roundup, if you want the fuller picture of where healthcare technology investment is heading in 2026.
Core Features of a Healthcare CRM System
Not every healthcare CRM needs every capability on this list. The right feature set depends on your org type, patient volume, and integration landscape. But these are the modules that appear in most production-grade systems.
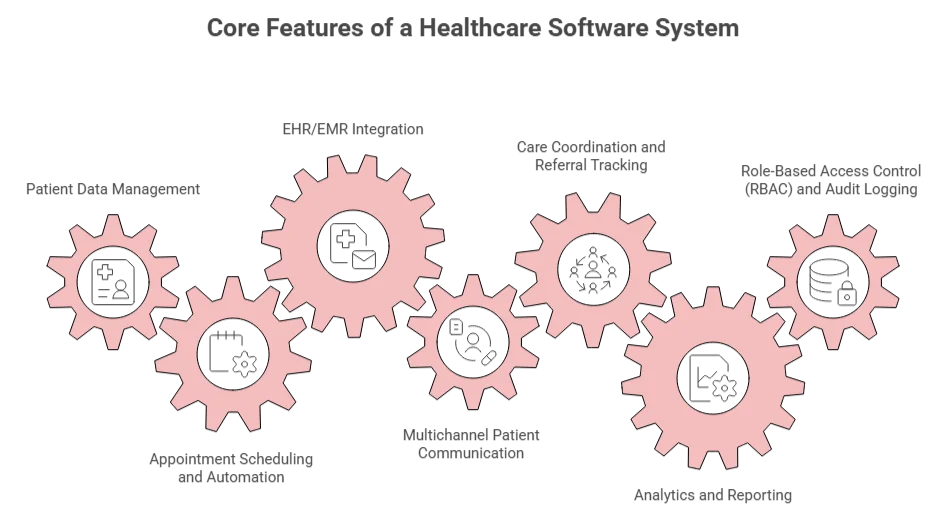
Patient Data Management
It is the foundation. A healthcare CRM needs a unified patient record that pulls from multiple sources, your EHR, scheduling system, and billing platform, and presents a coherent view without duplicating data. This requires careful data modeling to handle patient identity matching, consent tracking, and PHI tagging so the system knows which fields require encrypted storage and access controls.
Vick identifies a specific dimension of patient data that most system designers miss: the gap between clinical documentation and lived reality.
“I have encountered situations where providers made assumptions based on how I appeared during a brief appointment rather than the reality of how my conditions affect my daily life. Reading those notes helps me understand what they are seeing and gives me an opportunity to clarify information when necessary.”
Building in structured mechanisms for patients to flag discrepancies in their records, and for those flags to reach the right person, is a design decision, not an afterthought.
Appointment Scheduling and Automation
Automated reminders via SMS, email, and voice. Rescheduling workflows. No-show follow-up sequences. This module alone can materially move metrics, studies consistently show automated reminders reduce no-show rates by 20–40%, which at scale represents significant recovered revenue.
EHR/EMR Integration
It is the most technically complex module, and also the one most frequently underscoped. Your CRM needs to read patient demographics, encounter history, and active care plans from your EHR, and write communication records back. The data standard is HL7 FHIR R4 for modern integrations, with legacy HL7 v2 often required in parallel for older systems.
Multichannel Patient Communication
A unified inbox for SMS, email, and telephony. The architectural requirement is a single system of record for communication history, not separate tools that don’t talk to each other. This matters for continuity of care and for HIPAA audit compliance.
Vick is direct about where this breaks down in practice:
“The most frustrating communication challenge I face today is the increasing loss of direct communication with physicians. In the past, many concerns could be addressed through secure messaging. Increasingly, messages are routed through staff members or intermediaries who often respond with instructions to schedule another appointment. Questions that could once be resolved through a brief exchange now require additional appointments that consume time, energy, financial resources, and limited appointment availability.”
This is a workflow design problem as much as a technology one. A healthcare CRM that routes messages through configurable triage logic, instead of dumping everything into a generic inbox, directly addresses what Vick describes.
Care Coordination and Referral Tracking
For hospital networks and multi-specialty practices, referral management is often the highest-ROI module. This includes tracking outbound referrals, inbound referral conversion rates, and care team coordination workflows for patients with complex or chronic conditions.
Analytics and Reporting
This feature helps measuring patient engagement metrics, communication effectiveness, appointment adherence rates, and referral source attribution. For C-suite buyers, this is often the module that closes the build decision: the ability to see, in one dashboard, what the relationship layer of the organization looks like, and where it’s leaking.
Role-Based Access Control (RBAC) and Audit Logging
It’s not an optional feature but a necessity. Every user in the system has a defined role. Every role has defined permissions. Every access event, read, write, update, delete, gets logged with a timestamp and user ID. This isn’t just compliance architecture; it’s also how you limit blast radius when credentials are compromised.
HIPAA, GDPR & the BAA Question No One Is Asking Their Dev Partner
If you need a quick overview of what matters, here’s a brief HIPAA compliance checklist you can always refer to before signing any vendor:
| # | Compliance Requirement | What to Verify |
|---|---|---|
| PHI encryption at rest | AES-256 encryption applied to all stored patient data | |
| PHI encryption in transit | TLS 1.2 minimum enforced across all data transfers | |
| RBAC configured by clinical role | Access permissions mapped to specific roles — not generic user levels | |
| Audit log covering all PHI access events | Every read, write, update, and delete timestamped with user ID | |
| BAA signed before data access | BAA executed before any developer touches real or production-like patient data | |
| Breach notification procedure documented | Written process in place — who gets notified, in what timeframe, by whom | |
| Data destruction policy at project end | Vendor commits in writing to how PHI is destroyed or returned when engagement closes | |
| Testing environment uses de-identified data only | No real patient records used in dev or QA environments under any circumstances | |
| Penetration testing completed pre-launch | Third-party pen test conducted and findings remediated before go-live |
HIPAA compliance in a healthcare CRM comes down to three things: how you store data, who can access it, and what happens when something goes wrong.
The Storage Requirements Are Well Understood: Encryption at rest (AES-256 is standard), encryption in transit (TLS 1.2 minimum), PHI isolation from non-PHI data, and regular backups with documented retention policies. These are technical requirements your development partner should be implementing as defaults, not as add-ons.
Role-based access is the second layer. Not everyone in a healthcare organization should see everything. A referral coordinator doesn’t need clinical encounter notes. A billing staff member doesn’t need communication history. RBAC ensures that access is scoped to role, that privilege escalation is controlled, and that every access event is logged. The audit log isn’t just a compliance artifact, it’s your forensic record in the event of a breach.
The breach notification requirement is the third layer, and it’s the one that surfaces the question almost nobody asks during vendor selection.
There’s one more area that is often overlooked but carries major significance, it’s the BAA question.
The BAA Question
“Clients come in without a BAA sorted quite often, especially smaller organizations. The impact is immediate: it delays vendor approvals, production access, data migration, and security reviews. A missing BAA alone can push a project back two to eight weeks before a single line of code is written.” — Muhammad Arif, Technical Project Manager, AppVerticals
Under HIPAA, any vendor who stores, processes, or transmits Protected Health Information on your behalf is classified as a Business Associate. That includes your development partner, specifically, any developer who touches real or production-like patient data during build and testing. This legal classification requires a signed Business Associate Agreement before the engagement begins.
A BAA defines the vendor’s obligations around PHI handling: how they store it, who can access it within their organization, what they’ll do if there’s a breach, and how they’ll destroy or return the data at project end.
The problem: many healthcare organizations go through the full vendor selection process, reviewing portfolios, comparing pricing, checking technical capabilities, without ever asking whether the development partner will sign a BAA. And many development vendors who work in healthcare either aren’t clear on the requirement or haven’t standardized the process.
The question you can ask your vendors directly: ‘Before we engage, can you provide and sign a Business Associate Agreement?’ A qualified partner answers yes immediately and provides a template or accepts yours. Any hesitation, confusion about what a BAA is, or suggestion that it’s ‘probably not necessary’ for development work is a signal to keep looking.
For organizations operating in the EU or handling data from EU-based patients, GDPR adds a parallel layer, a Data Processing Agreement (DPA) is the GDPR equivalent of a BAA. If your patient base includes European residents, you need both.
Healthcare CRM Development Cost in 2026
The range you’ll see everywhere, $40,000 to $300,000-plus, is accurate. It’s also almost useless without context, because the spread is entirely explained by three variables: which EHR integrations you need, what your compliance scope looks like, and how many custom workflows the system needs to support.
If you’re also evaluating costs for other healthcare digital products alongside your CRM, our breakdown of healthcare app development cost covers how these variables shift depending on the product type you’re building.
| Category | MVP ($40K–$80K) | Mid-Market ($80K–$150K) | Enterprise ($150K–$300K+) |
|---|---|---|---|
| What’s included | Core patient data, appointment scheduling, basic multichannel communications, HIPAA architecture, RBAC, audit logging | Everything in MVP + single EHR integration, referral tracking, reporting dashboard, care coordination | Everything in Mid-Market + multiple EHR integrations, full clinical workflow automation, advanced analytics, enterprise RBAC, multi-site architecture |
| What drives cost up | Adding even one EHR integration moves you to the next tier | HL7 v2 support alongside FHIR requires two separate integration architectures | Each major EHR vendor implements FHIR R4 differently, so every integration requires vendor-specific logic |
| Ongoing cost (Year 2+) | $6,000–$12,000/year | $12,000–$20,000/year | $20,000–$35,000/year |
Budget 15–20% of initial build cost annually for security patches, feature iteration, and EHR API updates.
‘One feature request that consistently expands scope beyond initial estimates is the “single patient view”, an aggregated dashboard pulling data across multiple systems. It sounds straightforward. In practice it requires multiple integrations, data mapping, identity matching across systems, synchronization logic, and error handling. Scoping it properly at the start is the difference between a $10,000 line item and a project that quietly doubles. — Muhammad Arif, Technical Project Manager, AppVerticals
Custom Build vs. Salesforce Health Cloud vs. Off-the-Shelf SaaS: Which Is Right for You?
The cost ranges above assume you’ve already decided to build custom. That’s not always the right call, and committing to the wrong option for the right-sounding reasons is its own category of expensive mistake.
Three viable paths exist. Here’s the quick version, then the reasoning behind it.
| Category | Off-the-Shelf SaaS | Salesforce Health Cloud | Custom Build |
|---|---|---|---|
| Time to launch | 2–8 weeks | 3–6 months | 4–14 months |
| EHR integration depth | Pre-built connectors only | Standard + custom (expensive) | Full, vendor-specific |
| Customization ceiling | Low | Medium | None |
| Data ownership | Vendor-controlled | Vendor-controlled | Full ownership |
| 3-year cost (mid-market) | $60K–$120K | $130K–$220K+ | $100K–$170K |
| Best fit | Standard workflows, smaller teams | Salesforce-native orgs | Unique workflows, deep EHR needs |
Off-the-shelf SaaS
It works if your patient engagement workflows are standard, your team is under 30 users, and you don’t need EHR integration beyond pre-built connectors. These platforms are HIPAA-compliant out of the box, deploy in weeks, and for straightforward use cases, appointment reminders, basic outreach, simple referral tracking, they do the job without a full build. The ceiling arrives when your workflows stop fitting the template. At that point you’re engineering workarounds inside a system not built for them, and that cost compounds quickly.
Salesforce Health Cloud
It is genuinely useful for a specific type of organization: larger health systems already in the Salesforce ecosystem, with complex commercial and clinical workflows running in parallel, and internal admin capacity to configure and maintain it. For everyone else, it tends to be oversold. Licensing runs $300–$600 per user per month. Implementation partners rarely quote below $50,000 for setup alone. For a mid-market clinic group with specific EHR requirements, the three-year total frequently exceeds a purpose-built custom system , without the integration depth that made it worth considering.
Custom Development
It is the right call when your EHR integration requirements go beyond pre-built connectors, your workflows are specific enough that you’d spend significant money bending a platform to fit them, or you need full ownership of your patient data outside a vendor’s data model.
The three-year number matters more than the upfront cost. A $60,000 custom MVP maintained at $15,000 per year lands in roughly the same range as mid-tier Health Cloud licensing for a 20-user team, before implementation and admin overhead. That math shifts by user count, but the gap is consistently smaller than it looks at the point of decision.
If you’re still not sure which path fits, four questions tend to clarify it:
- Do you need bidirectional data sync with your EHR, not just read access?
- Will patients interact directly with the system in ways you need to control and brand?
- Do you have workflows that don’t map to a standard outreach or scheduling model?
- Is your patient data an asset you need to own across vendor relationships?
Two or more yes answers almost always point to custom, whether organizations start there or arrive after a costly detour through the other two.
These are the patterns we’ve seen across every healthcare CRM engagement we’ve scoped. If you want to pressure-test your current plan against them before you commit, → that’s exactly the conversation we start with.
The AppVerticals CRM Scoping Matrix
“Most clients come in assuming the technology is the hard part. What actually drives the number is workflow complexity, integration requirements, and compliance scope, not the software itself. A $90,000 quote and a $200,000 quote can both be right for the same org type, depending on those three variables.” — Muhammad Arif, Technical Project Manager, AppVerticals
Before you can pressure-test a vendor quote, you need a framework to sanity-check the number they give you. There are four inputs that determine your realistic cost band:
Input 1: Org type. Telehealth startup, clinic group, multi-specialty practice, hospital network, or digital health product. The org type determines the complexity of workflows, the number of user roles, and the likely EHR environment.
Input 2: EHR integrations required. Zero (manual inputs only), one (the most common), or multiple. Each major EHR integration adds $15,000–$35,000 to scope, depending on the vendor and whether real-time sync is required.
Input 3: Compliance scope. HIPAA only, HIPAA + GDPR, or additional state-level regulations (California CMIA, New York SHIELD Act). Multi-jurisdiction compliance adds audit complexity and affects data architecture decisions made early in the build.
Input 4: Feature tier. MVP (core engagement workflows only), mid-market (EHR integration + referral tracking), or enterprise (full clinical workflow automation + population analytics).
“The difference between a $40K project and a $300K project is rarely user count or software licenses. It’s almost always complex; multiple locations, multiple systems, custom patient journeys, enterprise security requirements. When someone gets a quote that’s outside this matrix without a clear explanation, that’s the conversation to have with your vendor before you sign anything.” — Muhammad Arif, Technical Project Manager, AppVerticals
| Org Type | EHR Integrations | Compliance Scope | Feature Tier | Realistic Cost Band |
|---|---|---|---|---|
| Telehealth startup | 0–1 | HIPAA | MVP | $45,000–$75,000 |
| Small clinic group | 1 | HIPAA | Mid-market | $80,000–$120,000 |
| Multi-specialty practice | 1–2 | HIPAA | Mid-market | $110,000–$160,000 |
| Hospital network (regional) | 2–4 | HIPAA + state | Enterprise | $180,000–$300,000+ |
| Digital health product (B2B2C) | 1 | HIPAA + GDPR | Mid-market to enterprise | $120,000–$220,000 |
If a vendor quotes you outside this range without explaining why, ask them to walk through the same four inputs. The right partner can justify every line of their estimate. Muhammad has significantly emphasized on how the type of organization matters most when it comes to calculations in his conversation. He specifically mentioned:
“Multi-location clinics almost always underestimate their own complexity. They think of themselves as one organization, but each location has typically evolved different workflows over time. The gap between a solo practice and a hospital system isn’t just user count. Its integration depth and governance complexity, and multi-location clinics tend to sit much closer to the hospital end of that spectrum than they expect.”
The EHR Integration Reality: What Your Dev Partner Should Tell You before You Sign Anything
EHR integration is the line item that blows healthcare CRM timelines most consistently. Not because it’s technically impossible, but because the time required to get production API access, before a single line of integration code is written, is longer than most project plans account for.
| EHR Vendor | Timeline | Week 1–3 | Week 4–6 | Week 7–10 | Week 11–14+ |
|---|---|---|---|---|---|
| Epic | 6–12+ weeks | MyApp registration | Security review | Technical validation | Health system IT governance → production access |
| Oracle Cerner | 6–10 weeks | Cerner Code application | Documentation review | Technical review | Approval & credentialing → production access |
| Athenahealth | 3–6 weeks | REST API application | Technical review | Approval | Production access granted |
⚠ Credentialing runs parallel to design and architecture work, but integration development cannot begin until production access is granted. Any project timeline that treats credentialing as a background assumption rather than a tracked workstream will slip.
The questions to ask before you sign:
- Have you worked with this specific EHR vendor before? In what context?
- How are you accounting for credentialing time in the project timeline?
- Do you support HL7 v2 alongside FHIR, or FHIR only?
- What happens if EHR vendor approval takes longer than scoped? Is the timeline padded or do we absorb the delay?
A development partner who’s done this before will answer these questions without hesitation. One who’s treating EHR integration as a standard API connection will either sidestep or underestimate them. If your product scope extends beyond CRM, a patient-facing app, a care coordination tool, or a broader digital health platform, our healthcare app development team has handled EHR integration across all major vendors.
Why Healthcare CRM Projects Go Over Budget: The 3 Mistakes We See Repeatedly
“One lesson I’ve learned from healthcare CRM projects is that the technology is usually the easier part. The real effort goes into understanding clinical workflows, regulatory requirements, and how different healthcare roles interact throughout the patient journey. Investing time in workflow discovery early in the project significantly reduces rework later, but most clients skip it, and that’s where the budget problems start.” — Muhammad Arif, Technical Project Manager, AppVerticals
Let’s take a detailed look at the areas Muhammad finds as repetitive client mistakes that cause healthcare CRM projects to go over budget:
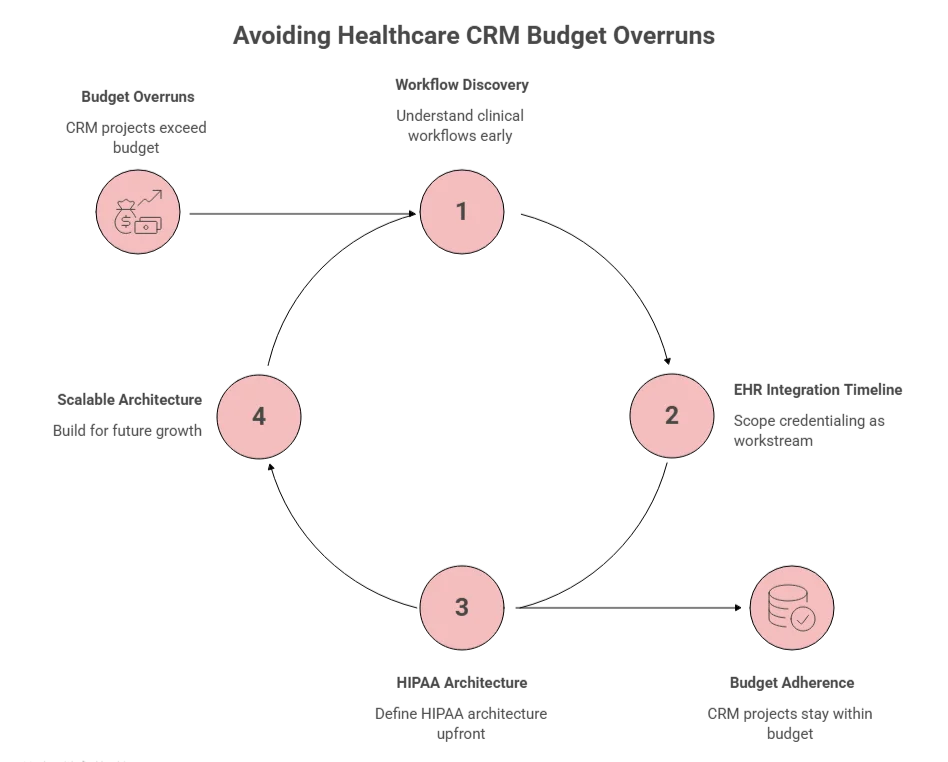
Mistake 1: Treating EHR Integration as a Checkbox, Not a Timeline
The most common budget-blower. A client scopes a 5-month CRM build, allocates 6 weeks for ‘EHR integration,’ and then discovers that Epic credentialing alone takes 10 weeks, before development has started. The project slips. The development team sits partially idle waiting for access. The client pays for the delay.
Muhammad particularly mentioned:
“Clients consistently expect EHR integration to take two to four weeks. The reality is six to sixteen weeks, depending on EHR vendor responsiveness, API maturity, and security review requirements. The integration itself is often not the bottleneck, access and approvals are. I’ve seen sandbox access alone delay a project by three months due to vendor approval queues and incomplete API documentation.”
The fix is straightforward: scope the credentialing process as its own workstream at the start of the engagement, run it in parallel with architecture and design work, and build the project timeline assuming the worst-case credentialing window, not the best case.
Mistake 2: Scoping HIPAA Compliance as a Feature, Not a Foundation
HIPAA compliance isn’t a module you add before launch. It’s an architectural decision that shapes everything from the database schema to the deployment infrastructure to the access control model. Muhammad highlights:
“Clients often assume their CRM vendor automatically covers HIPAA requirements. It rarely does. The things I most consistently have to flag are audit logging, access controls, data retention policies, and PHI storage locations, none of which were scoped upfront. When compliance gets treated as a late-stage checklist, it doesn’t take two weeks to fix. It takes six, after most of the budget is already spent.”
The right approach: define the HIPAA architecture before a single line of application code is written. Choose a cloud provider with a HIPAA BAA (AWS, Azure, and GCP all offer them). Structure the data model around PHI boundaries from day one. Implement RBAC and audit logging as foundational components, not add-ons.
Mistake 3: Building for Your Current Org, Not Your Next One
Healthcare organizations change. Practices acquire, merge, and expand. A CRM scoped for 15 users at a single-location clinic looks very different from one that needs to serve 80 users across four locations two years later.
The architecture decisions that govern multi-tenancy, user permission models, and database scaling are made early and are expensive to change later. An MVP doesn’t need to be enterprise-ready on day one, but it does need to be built on a foundation that doesn’t actively prevent scaling. This is a conversation to have before the architecture document is finalized, not after you’ve outgrown a system that wasn’t designed to grow.
How to Choose a Healthcare CRM Development Partner: 5 Questions That Separate the Right Partner from the Rest
Portfolio and price are obvious evaluation criteria but there’s a lot more to consider when choosing your healthcare CRM development partner. These five questions surface what portfolio and price can’t.
- ‘Have you worked with our specific EHR before, and can you show us the integration?’
Not ‘do you have EHR integration experience’, that’s too easy to claim. Specifically: have you integrated with this EHR, what was the scope, and can you walk us through how you handled the credentialing process and the integration architecture?
- ‘Will you sign a Business Associate Agreement before accessing any patient data?’
As covered earlier: this is legally required, not optional. Ask it directly. The response tells you immediately whether the partner understands HIPAA at an operational level or just a theoretical one. If there’s hesitation or confusion, walk away.
- ‘How do you handle compliance architecture, is it built from the start, or scoped as a separate phase?’
The right answer is ‘built from the start.’ Compliance-as-an-afterthought is the single biggest source of healthcare software cost overruns.
- ‘Can you walk us through a project that went over budget or timeline, and what caused it?’
This question doesn’t have a right answer, it has a revealing answer. A partner who can tell you specifically what went wrong, what they learned, and how they’ve changed their process is a partner who has actually shipped healthcare software under real conditions.
- ‘What does your post-launch support model look like?’
Healthcare software doesn’t stop needing attention after launch. EHR vendors update their APIs. HIPAA enforcement priorities shift. Your workflows evolve. You want a defined maintenance agreement, a clear SLA for critical bug fixes, and an explicit plan for handling EHR API updates.
Red flags to watch for:
- Cost estimates delivered without walking through your specific EHR environment and compliance scope
- No healthcare-specific portfolio, or a portfolio that blurs healthcare with general software
- Vague answers about the BAA
- A timeline that doesn’t explicitly account for EHR credentialing
- No dedicated QA process for PHI handling
The Build Decision Carries Consequences That Last Years
A healthcare CRM is not a commodity product. The compliance requirements, the EHR integration complexity, and the variation between org types mean the build decision, what to build, how to scope it, and who you build it with, carries consequences that last years.
Deborah Vick puts the human stakes plainly:
“The best healthcare communication creates partnership. Patients are not simply recipients of care; they are active participants living with their conditions every day. The healthcare organizations that communicate most effectively are the ones that recognize the value of both clinical expertise and lived experience, bringing them together to improve care for everyone involved.”
The organizations that get it right treat the development engagement like a clinical system: with documented requirements, a partner who understands the regulatory environment, and clear accountability for every component that touches patient data. The ones that get it wrong typically discover the gap during testing, after the budget is spent.
If you’re scoping a healthcare CRM build, the conversation you need to have is about scope, not just price. That’s where we start.
Ready to build it right?
See how we approach healthcare software development.
View our healthcare software development servicesGenerative AI in Business: Applications, Implementation Steps, and ROI Benchmarks
Despite the potential, 30% of generative AI pilots fail after proof of concept, often due to incomplete data, insufficient workflow integration, or unclear ROI (Gartner). Effective adoption requires selecting high-value workflows, preparing clean and accessible data, embedding AI into existing systems, and establishing governance and measurement frameworks.
This guide provides a step-by-step approach to generative AI in business, covering applications across functions, risk mitigation, implementation steps, and ROI benchmarks.
It also includes insights of a generative AI development company, giving executives and product leaders a practical framework to evaluate and deploy AI where it delivers measurable results.
What is Generative AI in Business?
Generative AI in business refers to AI systems that create, summarize, classify, or analyze content, code, designs, or data to support workflows and decision-making. It is distinct from the predictive AI organizations have used for years. Predictive AI tells you what is likely to happen next. Generative AI produces something new: a draft contract, a working code function, a customer response, a 10-page research summary distilled from 500 documents.
McKinsey estimates the long-term opportunity at $2.6 trillion to $4.4 trillion in additional productivity value from corporate use cases. That figure is the incremental productive output that AI makes possible when embedded directly into workflows.
Why Generative AI Matters for Businesses in 2026
Generative AI matters in 2026 because it has moved from experimentation into core workflow infrastructure, where businesses gain advantage by automating repeatable work, improving decision speed, and measuring ROI before scaling.
More than 50% of organizations now use generative AI in at least one business function, but adoption alone is not the real story. The real gap is between companies testing AI tools and companies redesigning workflows around them.
Accenture’s research found that organizations which have fully modernized AI-led processes achieve 2.5x higher revenue growth and 2.4x greater productivity compared to their peers. That gap is not closing. It is widening.
For business leaders, AI at scale is becoming part of business continuity, operating efficiency, and competitive planning.
In 2026, the question is not whether to adopt generative AI. The question is which workflows to target first, how to prove value early, and how to avoid the implementation mistakes that turn promising pilots into sunk costs.
Generative AI Business Applications by Function
The most effective way to evaluate generative AI for your organization is by function, not by technology.
Here is what other applications actually show.
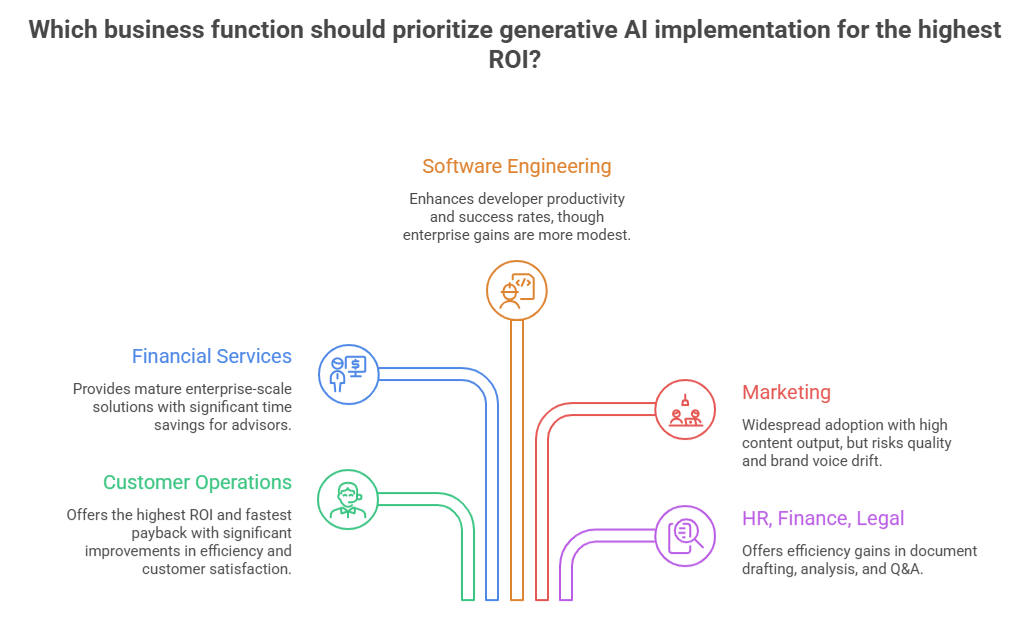
1. Customer Operations and Support
This is consistently the highest-ROI, fastest-payback function for generative AI. The Klarna case study is the most documented example at scale.
In February 2024, Klarna deployed an OpenAI-powered customer service assistant that handled 2.3 million conversations in its first month. The assistant resolved issues in under two minutes compared to 11 minutes for human agents, drove a 25% drop in repeat inquiries, and contributed to a projected $40 million profit improvement.
Human-AI ratio matters more than full automation. Klarna’s most durable gains came from AI handling tier-1 volume while humans focused on judgment-intensive cases.
2. Financial Services and Wealth Management
Morgan Stanley’s deployment of AI at Morgan Stanley Debrief is the most mature enterprise-scale wealth management implementation on record.
The system, built on OpenAI’s GPT-4 and launched in early 2024, indexed more than 350,000 proprietary research documents and made them queryable in seconds versus the 30-plus minutes advisors previously spent on manual research.
By late 2025, the tool had achieved 98% adoption among the firm’s wealth management advisors, with nearly 50% of all Morgan Stanley employees using generative AI tools.
3. Software Engineering
GitHub’s most rigorous study, a controlled experiment with 95 professional developers, found that access to GitHub Copilot reduced average task completion time from 2 hours 41 minutes to 1 hour 11 minutes, a 55% improvement in coding speed. Success rates also improved from 70% to 78%.
At the enterprise scale, a field experiment at Microsoft with 1,663 developers showed 12.92% to 21.83% more pull requests completed per week. At Accenture, a separate experiment with 311 developers showed 7.51% to 8.69% productivity improvements.
These numbers are smaller than the controlled lab results, which is expected. Enterprise codebases are more complex, and integration with existing tools takes time.
But they are consistent and measurable.
4. Marketing and Content Operations
Marketing is the function where generative AI adoption is most widespread and where measurement is most inconsistent. According to Salesforce, more than 60% of marketing leaders have already used generative AI for content creation.
The production efficiency gains are real: teams generating 5x more content output with the same headcount are not unusual. The risk, documented across multiple implementations, is quality and brand voice drift when AI-generated content bypasses editorial review.
5. HR, Finance, and Legal
HR teams use generative AI for job description drafting, resume screening, onboarding content, and employee policy Q&A. Finance teams have cut report drafting time by an average of 40 to 60% in production deployments. Legal teams use document review AI to cut contract analysis from hours to minutes.
A European bank replaced its rule-based customer chatbot with a generative AI version and found it 20% more effective at answering queries, with further improvements expected to double that figure.
Highest-ROI Generative AI Use Cases for Business
The highest-ROI generative AI use cases share three traits: high task volume, measurable output, and clear workflow ownership. Financial services currently leads on ROI, followed by media, telecommunications, mobility, retail, energy, manufacturing, healthcare, and education.
| Use Case | Real-World Evidence | Avg ROI Range | Time to Value |
|---|---|---|---|
| AI Customer Support Agent | Klarna: $40M profit gain, 85% faster resolution, 2.3M chats/month (Feb 2024) | 3x to 5x | 3 to 6 months |
| Internal Knowledge Assistant | Morgan Stanley Debrief: 98% advisor adoption, 350K+ docs indexed, seconds vs. 30 min | 2x to 4x | 6 to 12 months |
| Code Generation / Dev Assist | GitHub Copilot: 55% faster task completion, 12-22% more PRs/week at Microsoft | 3x to 6x | 4 to 8 months |
| Marketing Content at Scale | United Airlines: scaled from 15% to 50% flight coverage with same team | 4x to 8x | 2 to 4 months |
| Sales Enablement | Verizon: 40% sales increase, 95% query resolution, 100K churns prevented | 3x to 5x | 3 to 6 months |
| Document Automation (Legal/HR/Finance) | European bank: 20% lift over rule-based system; finance teams: 40-60% drafting time cut | 2x to 5x | 4 to 9 months |
Generative AI Implementation: A Step-by-Step Roadmap
Successful AI deployments take less than 8 months on average and organizations realize value within 13 months. That timeline is achievable. It is also frequently blown when organizations skip the foundational steps in favor of moving straight to model selection.

Here is the sequence that consistently produces results.
1. Define the business problem before touching any technology.
State the current process, the volume, the cost per unit, and the target outcome in measurable terms. ‘Customer support handles 10,000 tier-1 tickets per month at an average of 12 minutes each.
Target: resolve 60% through AI in under 2 minutes with equivalent satisfaction scores.’ That is a solvable problem. ‘We want to explore AI’ is not.
2. Audit data readiness before selecting any tool.
What data does this workflow require? Where does it live? Is it structured, clean, and accessible without violating privacy or compliance requirements?
3. Establish baselines and success metrics before the pilot begins.
Measure handle time, error rate, output volume, cost per task, and any other KPI you expect to move. Organizations that skip this step have no way to prove ROI, and without provable ROI, the program does not scale.
McKinsey’s AI survey found that organizations reporting significant financial returns are twice as likely to have redesigned end-to-end data workflows before selecting modeling techniques.
4. Select the right technical approach for your use case.
The five options, and when each applies, are covered in the Build/Buy/Customize section below.
5. Build the integration and governance layer alongside the model, not after it.
The integration connects the AI to your existing systems. The governance layer establishes output logging, human review queues, and monitoring.
Both must exist from day one in regulated or customer-facing deployments.
6. Run a time-boxed pilot with a real user group, not an internal demo.
30 to 60 days, defined user cohort, measurement against your pre-established baselines. Klarna’s production launch followed roughly 6 months of internal testing, alpha deployment, and limited beta rollout before going live across 23 markets. That pipeline is typical of implementations that succeed.
7. Evaluate against baselines.
If the pilot meets your ROI threshold, expand. If it does not, diagnose the gap before scaling. Most scaling failures trace directly to gaps that were visible in the pilot but ignored under pressure to move fast.
8. Establish continuous monitoring. AI models drift.
A system that performed at 90% accuracy at launch can degrade as your data, products, or customer base changes. Build monitoring into your operational model from the start.
What Architecture Does a Business GenAI System Need?
Most business AI deployments are not a single model. They are a stack of components, and the architecture you choose determines what the system can do, how reliably it does it, and how much it costs to maintain. Understanding the stack helps you evaluate AI development services, avoid vendor lock-in, and plan governance correctly.
The Five-Layer GenAI Architecture Stack
The 5-layer generative AI architecture stack includes foundation model layer, retrieval layer, orchestration layer, integration layer, and governance.
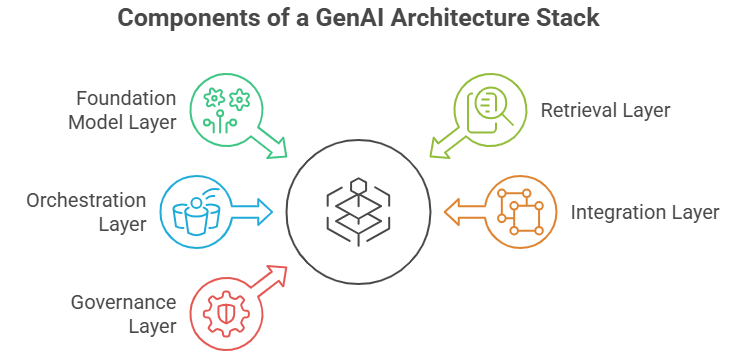
1. Foundation model layer:
The LLM is accessed via API (GPT-4o, Claude 3.5, Gemini, Llama 3, Mistral) or deployed on-premise for sensitive data environments. In 2026, more than 50% of enterprises are running an average of 4.2 AI models in production.
2. Retrieval layer (RAG)
A vector database or search index that retrieves relevant internal documents before each query, grounding model outputs in your specific data context. This is the layer that makes a general-purpose LLM behave like an expert in your domain.
3. Orchestration layer
Middleware such as LangChain, LlamaIndex, or custom-built frameworks that manage prompts, tool calls, memory, and multi-step reasoning. This layer is where workflow logic lives.
4. Integration layer
APIs and connectors linking the AI to your CRM, ticketing system, ERP, database, or communication tools. Without this layer, AI outputs do not reach the systems and people who need them.
5. Governance layer
Output logging, access controls, human review queues, bias monitoring, and performance dashboards. Companies are twice as likely to uncover AI failures when governance is in place.
AI agents add an action layer on top of this stack. Instead of just generating text or answers, agents call APIs, query databases, trigger downstream workflows, and complete multi-step tasks with minimal human input between steps.
Generative AI Risks and Governance Checklist
Approx. 40% of enterprises deploying generative AI cited content integrity and governance as one of their top three operational risks. Governance is not a compliance checkbox. It is an engineering requirement that determines whether your AI system remains reliable at scale.
The Six Core Risk Categories of Gen AI in Business
These include:
1. Hallucinations and factual errors
Models generate confident, coherent outputs that are factually wrong. In low-stakes workflows this is a quality problem. In legal, medical, financial, or regulatory contexts it is a liability. Every high-stakes output needs a human review checkpoint.
2. Data leakage and privacy exposure
Sending sensitive internal data to external model APIs without proper data processing agreements creates compliance exposure.
3. Model drift
AI systems degrade over time as your data, products, or customer base changes. A model that performed well at launch requires ongoing monitoring to catch drift before it affects output quality.
4. Prompt injection
Malicious inputs can manipulate AI agent behavior, particularly in systems where users control portions of the prompt context. This is a meaningful attack surface in customer-facing deployments.
5. Over-reliance and skill atrophy
Teams that stop applying critical judgment because the AI handles it create operational risk. Human oversight must be designed into the process, not bolted on after an incident.
6. Regulatory and IP risk
AI-generated content may reproduce copyrighted material. Outputs in regulated industries may conflict with disclosure requirements or fiduciary standards. These risks must be evaluated by function, not treated as uniform.
Governance Checklist by Priority
| Governance Control | Priority Level | Responsible Owner |
|---|---|---|
| Output logging and complete audit trail | Critical | Engineering |
| Human review checkpoint for high-stakes outputs | Critical | Operations / Legal |
| Data classification and role-based access controls | Critical | Security / Legal |
| PII and sensitive data handling policy | Critical | Legal / Compliance |
| Vendor data processing agreements | Critical | Procurement / Legal |
| Model performance monitoring dashboard | High | Engineering / Analytics |
| Bias detection and fairness audits | High | Quality / Compliance |
| User training on AI limitations and failure modes | High | HR / L&D |
| Incident response plan for AI failures | High | Operations |
| Periodic output quality spot-checks | Medium | Quality Assurance |
Why Generative AI Projects Fail After Proof of Concept
Data quality failure.
The model is only as good as the data behind it. If the source data is incomplete, outdated, duplicated, or trapped across disconnected systems, the output becomes unreliable no matter how strong the model is.
No measurable business objective.
Projects started with ‘let’s explore AI’ rarely scale. Without a defined metric and baseline, there is no way to declare success or justify continued investment.
According to Fullstack, only 15% of US employees report that their workplaces have communicated a clear AI strategy.
Workflow integration failure.
AI deployed on top of a broken or poorly documented process does not fix the process. It accelerates the dysfunction. Generative AI reveals workflow problems it cannot solve on its own. The pre-integration audit is not optional.
Change management underinvestment.
Teams that do not trust AI outputs either do not use them or over-correct for errors in ways that eliminate the efficiency gain. High adoption rates require training, communication, visible leadership involvement, and workflow redesign that makes AI use natural rather than forced.
Cost overruns without ROI tracking.
Organizations spend on model API costs, infrastructure, and integration without tracking savings or revenue impact. When CFOs ask what they got for the investment, there is no answer.
Governance gaps causing incidents.
One data leakage event or AI-generated error in a regulated context can end a program. Governance cannot be retrofitted after deployment.
How to Measure ROI from Generative AI in Business
Measuring it requires a framework, not a gut feeling.
ROI Measurement Framework by Value Bucket
This is the measurement framework AppVerticals applies when establishing baselines with clients before an AI pilot begins.
| Value Bucket | What to Measure | How to Measure It |
|---|---|---|
| Labor efficiency | Hours saved per task per week across the user group | Time tracking pre/post; manager surveys |
| Process velocity | Cycle time reduction: from request to output | Ticket close time, content turnaround, report generation time |
| Output quality | Error rate, rework frequency, customer satisfaction | QA audits, revision tracking, NPS/CSAT |
| Decision speed | Time from question to actionable insight | Stakeholder surveys, report timestamps |
| Revenue impact | Pipeline influenced, conversion lift, retention | CRM attribution, cohort analysis, A/B testing |
| Cost avoidance | Headcount not added relative to output growth | Capacity planning models, annualized labor cost |
TCO vs ROI Comparison
| TCO Factor | What to Include | Why It Matters for ROI |
|---|---|---|
| Model usage cost | API calls, token volume, inference, fine-tuning | High usage can reduce ROI if costs are not tracked by workflow. |
| Infrastructure cost | Cloud hosting, vector database, monitoring tools | AI systems need supporting infrastructure beyond the model itself. |
| Integration cost | CRM, ERP, helpdesk, database, or internal API connections | ROI improves only when AI is connected to real workflows. |
| Governance cost | Audit logs, access controls, human review, compliance checks | Risk control is part of operating cost, not an optional layer. |
| Maintenance cost | Prompt testing, model updates, monitoring, retraining | AI performance changes over time and requires active upkeep. |
| Training cost | User onboarding, workflow training, adoption support | Teams need clear usage rules to turn AI output into business value. |
Build, Buy, or Customize: Which Generative AI Approach Fits Your Business?
This is one of the most consequential decisions in a generative AI program. The wrong choice wastes money. The right choice depends on three factors: workflow complexity, data sensitivity, and internal technical capacity.
| Approach | Best Fit | Examples | Core Advantages | Core Limitations |
|---|---|---|---|---|
| Prebuilt SaaS tools | Standard, high-volume tasks with no proprietary data requirements | ChatGPT Enterprise, Jasper, Copy.ai, Notion AI | Fastest to deploy; lowest cost to start | Limited customization; no internal data integration |
| API-based LLM | Custom prompt workflows where you control the context | OpenAI API, Anthropic API, Google Vertex AI | Flexible; scalable; no vendor UI lock-in | Requires dev capacity; prompt engineering expertise needed |
| RAG system | Internal knowledge retrieval where answers must come from your data | Custom doc search, contract analysis, HR policy Q&A | Grounded in your specific context; reduces hallucinations significantly | Data preparation is intensive and ongoing |
| Fine-tuned model | Domain-specific output patterns that general models do not replicate | Industry-specific language, proprietary writing style, specialized classification | High accuracy on the target task | Expensive to train; requires labeled data and MLOps expertise |
| AI agents | Multi-step autonomous workflows that require tool use and decision-making | Support ticket resolution, sales outreach, data pipeline orchestration | Handles complexity that single-turn LLMs cannot | Highest governance requirement; production failure modes are non-trivial |
Most organizations start with prebuilt or API tools and customize incrementally as adoption grows and requirements become clearer. Jumping to fine-tuning or custom AI agents on day one is almost always premature.
AI development services become relevant when your workflow complexity exceeds what prebuilt tools support, your data is too sensitive for third-party processing, or your process requires a custom integration architecture.
A qualified AI development partner designs and builds the system to your specifications, integrates it with your existing stack, and hands off with documentation and monitoring in place.
How to Choose the First Generative AI Use Case
The ideal first use case scores high on volume, labor intensity, and measurability, and low on risk. Customer support ticket handling, marketing content drafts, and internal document search consistently meet this profile across industries.
Use Case Selection Scoring Matrix
AppVerticals uses this scoring model to evaluate which use case a client should build first.
| Selection Criterion | High Priority Signal (Score: 3) | Moderate Signal (Score: 2) | Low Priority Signal (Score: 1) |
|---|---|---|---|
| Task volume | 100+ occurrences per week | 25 to 99 per week | Fewer than 25 per week |
| Labor intensity per task | 30+ minutes per occurrence | 10 to 30 minutes | Under 10 minutes |
| Output measurability | Clear quantitative KPI within 60 days | Measurable but longer lag | Subjective or difficult to quantify |
| Data readiness | Clean, accessible, structured, compliant | Partial gaps, fixable in 30 days | Scattered, inconsistent, or siloed |
| Risk level | Low stakes; errors are reversible | Moderate stakes with review step | High stakes; irreversible or regulated |
| User receptiveness | Team actively interested and involved in scoping | Neutral; willing to try | Active resistance or skepticism |
Avoid starting with the most complex, most sensitive, or most politically charged workflow in your organization. Win with a simple problem, prove the model, build internal credibility, then tackle the harder problems.
Conclusion
Generative AI delivers business value when applied to well-defined workflows with clear baselines, clean data, and governance built in from the start. The organizations producing the highest returns are winning because they disciplined their implementation, measured obsessively, and scaled only what was proven.
The high failure rate across generative AI pilots shows how often organizations skip the foundational work. Data readiness, workflow integration, human-AI ratio calibration, and governance are not optional steps. They are the work. For more expertise, explore our case studies.
Evaluating which generative AI use cases to prioritize?
AppVerticals helps you consider whether to build a custom AI system or deploy a prebuilt solution for your business.
Explore Generative AI development servicesAndroid App Development Outsourcing: What Works, What Fails, and How to Get It Right

Outsourcing Android app development means hiring an external team to build and maintain your Android app. It works when you need platform-specific expertise fast and can’t justify a full-time Android hire at US market rates ($100,000–$125,000/year). It fails when the vendor treats Android as generic mobile development, and you usually won’t find out until you’re deep into a rebuild.
The founder who got burned wasn’t careless. They checked portfolios, read reviews, and got on discovery calls. What they missed: the vendor routed the work through a Flutter generalist team, never asked which Android OS versions their users ran, and scoped against a feature list instead of a user flow. None of it was visible at signing.
This guide covers how to structure the decision, the engagement, and the relationship, so you end up with a working app, not a rebuild.
Key Takeaway
- The native vs. cross-platform decision is yours to make: Understanding what your product actually needs, hardware integration, device fragmentation exposure, iOS parity, before you brief a vendor means you can evaluate their recommendation confidently rather than take it on faith.
- A discovery sprint is the most underused risk-mitigation tool in outsourcing: A paid, time-boxed sprint ($2,000–$8,000) tells you more about a vendor’s real capabilities than any portfolio or sales call.
- Fixed-price contracts feel safe but often aren’t. The vendor prices in uncertainty you haven’t specified yet, and when scope disputes arise, you’re the one who absorbs the cost.
- Post-launch is where most outsourcing relationships quietly fail: Bug severity definitions, OS update compatibility commitments, and Play Store policy responsibilities should all be in your contract before you sign, not negotiated after something breaks.
- IP ownership means nothing without code accessibility: Your repo must be the working repo from day one. A signed assignment clause is worthless if the codebase is undocumented and the only person who understood it has stopped returning messages.
- The engagement model should match your stage: Fixed-price for defined MVPs, T&M with milestone gates for active development, dedicated team for 12+ month roadmaps, each protects you differently, and choosing the wrong one compounds every other risk.
When Outsourcing Android Development Actually Makes Sense (And When It Doesn’t)
Android commands roughly 70% of the global mobile OS market, running on approximately 3.9 billion active devices worldwide. In markets across Africa, Latin America, and South and Southeast Asia, that share exceeds 85%. If your users are anywhere outside the US and Western Europe, building an Android product isn’t one option among several, it’s the primary distribution channel.
The business case for outsourcing typically comes down to one of three realities.
The cost of in-house expertise doesn’t match your stage.
The 2025 Dice Tech Salary Report puts the average US software developer salary at $128,386, with mid-level engineers earning $100,000–$125,000. A senior Android engineer with current Jetpack Compose experience, Play Store deployment history, and real familiarity with device fragmentation sits at the high end of that band, before benefits, onboarding, or ramp time. For a startup or early-growth company whose product hasn’t yet proven market fit, that’s a difficult commitment to justify.
Your timeline is shorter than in-house hiring allows.
Finding, interviewing, and onboarding a senior Android developer takes three to five months on a good run. Outsourcing compresses that to weeks. When your roadmap has a hard external date, a partnership launch, a funding milestone, a platform dependency, that gap matters.
Your scope is defined enough to contract.
Outsourcing works best when the work can be scoped, delivered, and measured. If you’re still in discovery, genuinely uncertain what the product needs to do, outsourcing introduces alignment risk that an internal product conversation resolves faster and cheaper.
When It Doesn’t Make Sense
If Android development is the competitive core of your product, if the app is the product in a way that demands daily, tightly integrated engineering, outsourcing introduces handoff latency that compounds at each iteration.
Consumer social apps, real-time communication products, and anything requiring deep OS-level integration (Bluetooth LE, NFC, background processing constraints specific to manufacturer implementations) carry meaningfully higher outsourcing risk. The feedback loop between product and engineering needs to be short, and outsourcing stretches it.
However, before making a final decision, it’s worth understanding the full economics of outsourcing versus building internally. Whether you’re evaluating freelancers, a dedicated development team, or a mobile app development company with Android expertise, cost visibility is essential to making the right call.
The best place to start is with a detailed breakdown of Android app development costs. Understanding how pricing changes based on app complexity, team structure, geographic location, and long-term maintenance requirements will help you evaluate potential partners more effectively and avoid budget surprises later.
The Native vs. Cross-Platform Decision, And Why Your Vendor’s Answer Might Not Be Neutral
When you ask an outsourcing vendor whether to build natively in Kotlin or cross-platform with Flutter or React Native, you’ll get a confident answer. That answer reflects their team composition at least as much as it reflects your product requirements.
A vendor whose bench is primarily Flutter developers will make a compelling case for Flutter. A vendor with strong Kotlin engineers will explain why native is the right choice. Both will give you technically defensible reasoning. The problem is that you’re evaluating the reasoning without access to the context that shaped it.
Here’s a quick look at what factors you can look at when choosing between native and cross-platform:
| Criteria | Native Kotlin | Flutter | React Native |
|---|---|---|---|
| Hardware & platform integration (Bluetooth, NFC, camera, background processing, OEM-specific APIs) | Strong fit | Partial fit | Poor fit |
| Device fragmentation exposure (Sub-$200 devices, Xiaomi / Transsion / OPPO OEM variants, Android 10–15 range) | Strong fit | Partial fit | Poor fit |
| iOS parity required (Simultaneous Android + iOS launch from a shared codebase) | Poor fit | Strong fit | Strong fit |
| UI complexity (Custom animations, platform-native feel, complex layout requirements) | Strong fit | Strong fit | Partial fit |
| Long-term maintenance (Talent availability, Google Play compliance, OS update compatibility) | Strong fit | Partial fit | Partial fit |
| Timeline pressure (Fastest path from brief to Play Store for an API-driven product) | Partial fit | Strong fit | Strong fit |
| Post-launch flexibility (Ability to swap vendors, hire in-house, or extend the codebase cleanly) | Strong fit | Partial fit | Partial fit |
If you’re still not sure, this is worth understanding in detail, because getting the technical approach wrong at the start of a project isn’t a minor error, it surfaces as a rebuild six to twelve months later.
Native Android (Kotlin) is the right call when:
- Your app requires deep platform integration, Bluetooth LE, NFC, camera APIs, biometric authentication flows, or background sync behavior that varies by manufacturer.
- You’re building for a wide and fragmented device pool: Sub-$200 devices, older OS versions, or regional OEM brands like Xiaomi, Transsion, or OPPO that implement Android differently from flagship Samsung or Google Pixel hardware.
- Play Store compliance and Google’s target API level requirements are central to your go-to-market: Google’s developer documentation is explicit: apps must target the latest API level to submit updates, and older-style XML layouts and background processing patterns are increasingly flagged.
- You need Jetpack Compose for complex, performant, and customized UI: Google’s Android Developers Blog describes the shift toward Compose as a platform-wide transition, not an optional upgrade, vendors still building entirely in the legacy XML/View system are working against the grain of where Android development is heading
Cross-platform (Flutter, React Native) makes sense when:
- You’re building simultaneously for Android and iOS and your UI is relatively standard, forms, dashboards, catalogues, data display.
- A shared codebase matters more than platform-specific optimization.
- Your app is primarily API-driven rather than hardware-reliant.
The test to run on any vendor:
Ask directly: “What does your team’s composition look like? How many Kotlin/native Android engineers do you have versus Flutter developers?” A vendor with genuine Android expertise will answer that question without hesitation and will be able to explain specifically how they’d handle any platform-specific requirements in your use case. A vendor optimised for their own team’s convenience will redirect toward cross-platform benefits.
The cost of getting this wrong is not a line item, it’s a rebuild. A cross-platform app that crashes on 20–30% of your user base because of manufacturer-specific Android behavior isn’t a bug. It’s an architectural mismatch that doesn’t have a patch.
If you’re also working through the native vs. cross-platform decision in detail, our guide covers the full technical and commercial comparison, answering all your queries.
If you’re also working through the native vs. cross-platform decision in detail, our guide covers the full technical and commercial comparison, answering all your queries.
How to Vet an Android Outsourcing Partner without a Technical Background
The core challenge is that the people best placed to evaluate an Android development partner are Android developers. If you don’t have one, you’re working from indirect signals, and vendors know it.
Portfolio reviews, case study pages, and client testimonials are all necessary starting points. None of them are sufficient. A well-produced case study tells you that the vendor is good at producing case studies. It tells you significantly less about whether the senior Kotlin engineer from the pitch will be on your project, or whether they even have one.
Here’s what actually differentiates strong vendors from strong pitches.

Ask about their Play Store release history specifically.
Not whether they build Android apps, ask how many apps they’ve shipped to the Play Store in the last 18 months, what the average ratings are, and whether any have faced compliance rejections for target API level requirements.
A vendor with genuine Android experience will have specific, non-defensive answers. A vendor whose Android work runs through a generic mobile team will pivot.
Ask who does the work, not who’s in the room.
Ask directly: “If we move forward, who specifically would be on this project? Can I meet them before we sign?” Legitimate partners accommodate this readily.
A vendor who hedges on team composition before signing is almost certainly planning to staff the project differently from how they pitched it.
Request a code review of a live project.
You don’t need to evaluate the code technically. You’re evaluating whether they’ll share it. A vendor who won’t show you code from a previous project, even a public or deprecated one, is protecting something.
A vendor who provides a repository link and offers to walk you through the architecture in plain language is demonstrating both technical confidence and the communication quality your project will depend on.
Test their Android knowledge with one question.
Ask: “How do you handle Android OS version fragmentation across a typical user base?”
There’s no single correct answer. But a vendor who can’t explain their approach, which OS versions they target, how they test across manufacturer variants, how they handle background processing constraints that differ between Android 11 and Android 14, doesn’t have the platform depth the question exposes.
The Discovery Sprint: The Risk-Mitigation Tool Most Clients Skip
The single most effective way to evaluate an outsourcing partner is to pay them to do a bounded piece of work before you commit to a full engagement.
A discovery sprint is a paid, time-boxed engagement, typically one to three weeks, costing between $2,000 and $8,000, where the vendor scopes your project in detail, asks clarifying questions, and produces a technical architecture proposal or detailed specification. It’s not a free consultation. It’s a paid work sample.
What you’re evaluating is the process, not the deliverable.
A bad discovery sprint costs $5,000. A bad full engagement costs $50,000. The pattern of discovery sprints saving clients from the wrong vendor is consistent enough that we recommend them for almost every engagement above $25,000.
The Three Mistakes Clients Make Before They Sign Anything
These patterns discussed below show up consistently when engagements go sideways, usually within the first 60 days. Zaid Trimizi, Senior Customer Success and Product Manager at AppVerticals, has sat across the table from enough clients to know exactly where the cracks form.
Scoping by feature list instead of user flow.
A founder comes in with a tidy spreadsheet. Login, onboarding, dashboard, notifications, settings, twelve features, each with a one-line description. The vendor quotes against it. Everyone shakes hands.
Six weeks later, nobody can agree on what “notifications” actually meant. Does it cover the state where a user has denied Android notification permissions entirely? Does it handle the edge case where a background sync fails on a Xiaomi device running a heavily modified Android skin? The spreadsheet didn’t say. The contract didn’t either. Now it’s a dispute.
“The feature list tells me what a client wants to exist. The user flow tells me what the app actually needs to do. Those are two different documents, and most clients only bring one of them to the first call.” — Zaid Trimizi, Senior Customer Success & Product Manager, AppVerticals
A feature list negotiation produces a contract. A user flow conversation produces a specification. Contracts get disputed. Specifications get built. Before you sign anything, ask the vendor to walk through your primary user journeys end-to-end, not feature by feature, but as a user would actually experience them. Where they ask incisive questions, note it. Where they ask none, pay attention.
Choosing fixed-price because it feels like the safer option.
The logic is understandable. A fixed number feels like a ceiling. It feels like the vendor is absorbing the risk. What’s actually happening is more complicated.
Zaid has watched this play out repeatedly as he mentions: a client signs a fixed-price contract for an Android app at $35,000, relieved to have a hard number. Eight weeks in, a scope dispute emerges over something that seemed obvious to the client but wasn’t written into the spec. The vendor stands their ground, correctly, contractually. The client either pays more or accepts less. Neither outcome was what they thought they were buying.
The reason is incentive misalignment. A fixed-price vendor is optimised to close the contract and deliver to the letter of the spec, not to build something that performs consistently across your user base’s actual devices. Edge cases, performance considerations on sub-$200 handsets, manufacturer-specific Android behavior, these live outside the spec. So they often don’t get built.
For most Android projects in the $20,000–$80,000 range, a time-and-materials engagement with clearly defined milestone gates is a more reliable structure. It gives you real visibility into where time is going, the ability to reprioritise as you learn, and a vendor whose incentive is to work efficiently rather than to minimize scope interpretation.
Treating the PM as the technical decision point.
This one is subtle, and Zaid considers it the most common mistake non-technical clients make once the project is underway.
A client without an engineering background naturally gravitates toward the PM, they’re responsive, they speak in plain language, and they’re explicitly there to be the bridge. So every question goes through them. Architecture concerns, scope changes, technology decisions, all filtered through a single coordination layer.
What the client receives isn’t the engineer’s answer. It’s the PM’s interpretation of it. By the time a technical concern has been raised by the client, processed by the PM, discussed internally, and reported back, something has usually been lost, or softened.
“I always tell clients: you don’t need to understand the code to talk to the engineer. You just need to be in the room when the important decisions get made. If you’re only ever talking to the PM, you’re not in that room.” — Zaid Trimizi, Senior Customer Success & Product Manager, AppVerticals
Insist on direct access to the lead engineer for architecture decisions, scope changes, and anything involving a shift in technical direction. Make it a condition before you sign, not a request you make three months in when something has already gone wrong.
50,000 Downloads, Zero Technical Background: What a Real Outsourcing Engagement Looks Like
Isaac Knable had a clear product vision and no engineering background. A wrestling coach with over 20 years on the mat, founder of a wrestling academy, and inventor of the Footwork Trainer, he wanted to build Stance and Motion, a mobile app to help wrestlers at every level, from youth beginners to competitive athletes, develop footwork and movement mechanics from home, with no equipment required.
The idea had been sitting with him since 2018. Getting it built was a different matter entirely.
Speaking on AppTalk, Isaac described the vendor selection process with the kind of honesty that doesn’t usually make it into case studies. He’d considered freelancers, spoken to high school connections, and eventually narrowed the field to three candidates, a process he described as long, research-heavy, and deliberately careful. What tipped the decision toward AppVerticals wasn’t portfolio depth or price. It was the energy in the conversation, the confidence the team brought, and, critically, the references. Isaac reached out to people who had already built apps through AppVerticals and asked them directly what the experience was like.
“I got it down to about three people… I reached out to a couple people that had built apps and they pretty much told me straight what I was getting into. That sounded good to me. So I just kind of pulled the trigger.” — Isaac Knable, creator of Stance and Motion, on AppTalk
What follows is a useful illustration of how a non-technical founder should manage an outsourced build. Isaac’s own reflection on what he’d do differently was specific: he’d check in more. Not because anything went wrong, but because the instinct to trust the team and step back can quietly become a gap in communication that costs you later.
“If I was giving advice to somebody coming in, just keep communicating. I was maybe more willing to put trust in the team to do the job, but I should have been more willing to check in.” — Isaac Knable, AppTalk
When he did reach out, the response was there. Messages answered within the hour. The PM, Muhammad, described by Isaac was consistently available and reliable throughout the process.
The outcome: Stance and Motion launched on both Android and the Apple App Store, crossed 30,000 downloads in its first year, and, in Isaac’s own words, ended up “10 times better than what I originally had in my mind.” His high school coach’s voice is recorded into the app’s drill instructions, a detail that came together through a simple iPhone recording and editing by the AppVerticals team.
The app has been largely self-sustaining for months without active development pushes, running on organic reach while Isaac focuses on marketing through his own social channels.
The story isn’t remarkable because everything went smoothly. It’s useful because Isaac is precise about where the friction was, budget pressure, post-launch bug anxiety, the learning curve of understanding what “device issues” actually means, and honest that the communication discipline was something he had to learn through the process, not something he arrived with.
That’s the reality of most successful outsourced builds. The technical execution is only part of it. The client’s willingness to stay engaged, ask questions, and check in consistently is the variable that most directly determines how well the vendor can serve them.
Engagement Models: Which One Protects You at Each Stage
The Deloitte 2024 Global Outsourcing Survey found that 80% of executives plan to maintain or increase their third-party outsourcing investment. The same survey identified outcome-based and milestone-structured engagements as the fastest-growing delivery models, which reflects a market that has learned, broadly, that open-ended vendor relationships without defined measurement points tend to drift.
There are three standard engagement models for Android outsourcing. The right one depends on where you are in the product lifecycle.
Here’s a quick look at the engagement models you can choose from before we go into details:
| Fixed Price | Time & Materials | Dedicated Team | |
|---|---|---|---|
| Best for | Defined MVP, single module | Active development, evolving scope | Long-term roadmap, scaling |
| Cost predictability | High | Medium (with milestone gates) | Medium–High |
| Flexibility | Low | High | High |
| Client control | Low after signing | High | High |
| Typical range | $15K–$80K | $20K–$150K+ | $8K–$25K/month |
| Primary risk | Scope disputes | Budget overrun without gates | Team composition drift |
Fixed Price
Best for bounded, stable-scope work: a defined MVP with a locked feature set, a specific module, a UI redesign with clear deliverables.
The appeal is cost predictability. The risk is that fixed-price projects require a specification detailed enough that there’s no interpretive room in “done.” Most clients don’t have that specification before they sign. Most vendors price against the specification they have, which is always incomplete.
Use fixed-price when the scope is genuinely stable and you’ve already run a discovery sprint that produced a detailed technical spec. Don’t use it as a substitute for scoping.
Time and Materials (T&M)
Best for active product development with requirements that will evolve. Payment is tied to time logged and milestones reached, not to a pre-defined deliverable.
The risk is budget overrun without controls. T&M without milestone gates is a blank cheque. T&M with clearly defined two-week milestones, where each gate requires a demo or deployment, is a fundamentally different and significantly safer arrangement. The milestone structure is the protection, not the model itself.
Dedicated Team
Best for ongoing development where the outsourced team functions as a de facto internal engineering function, typically when you have 12+ months of roadmap, consistent development volume, and the economics of a monthly retainer ($8,000–$25,000/month for a typical Android team) compare favorably against fully-loaded US hiring costs.
The specific risk with dedicated teams: composition drift. The senior engineers who open the engagement often see attrition handled unilaterally by the vendor, a mid-level developer replaces a senior one without it being flagged as a change. Require contractually that any team composition change is communicated and subject to your approval.
Thinking through Android outsourcing for your own product?
We help founders and product managers navigate these decisions before they become expensive mistakes. No pitch, just clarity.
What Post-Launch Support Should Actually Cover (And What Most Contracts Leave Out)
The engagement doesn’t end at launch. For most Android apps, launch is where the real operating environment begins, and it’s significantly more complex than the development environment.
An Android OS update changes background process permissions. Google updates its target API level requirements and flags apps that haven’t complied for Play Store removal. A manufacturer pushes a custom Android skin that breaks a background sync process on 15% of your user base. A third-party SDK used in the build reaches end-of-life. None of this is unusual. All of it is inevitable over a 12-to-24-month window.
A typical outsourcing contract’s post-launch section amounts to: “We’ll provide 30 days of bug fixes.” That clause is not a support agreement. It’s a cooling-off period.
A real post-launch support contract covers the following.
Bug severity definitions with explicit response time SLAs.
Critical bugs, app crashes on launch, payment flows broken, authentication failures, should have a response commitment within 4 hours and a resolution SLA of 24–48 hours. Major issues, features unavailable, data display errors, should be addressed within 24 hours.
Minor issues, UI inconsistencies, edge-case rendering, can roll into the next sprint cycle. Without these definitions, every post-launch conversation starts with an argument about severity.
Android OS update compatibility commitments.
Google releases a major Android version annually. Manufacturer overlays add further variance. Your contract should specify that the vendor is responsible for maintaining compatibility with new major OS versions for a defined period, typically 12 months post-launch, at a pre-agreed rate, whether covered by a retainer or billed at a defined hourly rate.
Google’s Play Store requirements mandate that all new app updates target the latest API level; a vendor not actively monitoring these requirements will leave you scrambling to comply on a deadline you didn’t know was coming.
Play Store policy change responsibility.
Google’s Play Store policies update frequently, privacy permission declarations, content policy requirements, billing API changes. When a compliance update is required, who owns the cost?
The general principle: if the change is driven by an external policy or platform shift (Google’s requirements, a third-party SDK, a deprecated API) rather than a defect in the original build, the cost structure should be pre-negotiated rather than disputed under pressure.
Retainer structure vs. per-ticket billing.
A monthly retainer covering a defined block of hours, typically 10–20 hours for a stable app, is more predictable than per-ticket billing, which turns every request into a scope negotiation. For apps with active user bases or dependent third-party integrations, the retainer model protects you from the scenario where a critical fix sits for three days while a vendor waits for commercial approval.
Knowledge transfer requirements.
If you ever want to move development in-house or switch vendors, your contract should define what a proper handoff requires: inline documentation, a maintained README that a new developer can actually follow, architecture decision records (ADRs) for non-obvious design choices, and a defined handoff sprint, typically two to four weeks, where the outgoing team walks the incoming team through the codebase.
Without this defined in writing, handoff quality depends entirely on goodwill. Goodwill is plentiful when the relationship is warm. It’s absent when it isn’t.
Protecting Your IP, Code Ownership, and What Happens When the Relationship Ends
You can find detailed explanation of why you need to check-box each of the above-mentioned areas below:
IP ownership is standard outsourcing advice. Getting it right in practice requires more specificity than most contracts provide.
The standard guidance, “make sure your contract includes IP assignment”, is necessary but not sufficient. An IP assignment clause covers who legally owns the code at signing. It doesn’t address what happens to the code’s usability when the relationship ends, which is the practical risk that actually affects clients.
You can own the IP and still have a codebase that’s practically inaccessible: undocumented, architecturally opaque, built on internal tools and library configurations that only the original vendor knows how to navigate. Ownership without accessibility isn’t protection.
Your repository should be the working repository from day one.
Not a mirror, not a periodic export, the repository the vendor commits to should be under your account and your control from the first line of code. If the relationship ends for any reason, termination, vendor insolvency, a commercial dispute, you have a complete, current codebase immediately.
The pattern that causes real damage: vendors maintaining an internal “working” repo and pushing updates to the client’s repo periodically. The client is always behind, always dependent.
Documentation standards belong in the SOW, not in goodwill.
Specify minimum documentation requirements as a deliverable: inline comments for non-obvious logic, a maintained README, ADRs for architecture decisions. These take no significant extra time when built from the start.
They take substantial time and goodwill to retrofit, and retrofitting usually happens only when the relationship is already under strain.
Require a maintained third-party dependency inventory.
Every Android app has dependencies: Retrofit for networking, Glide for image loading, Dagger or Hilt for dependency injection, Firebase for analytics, payment SDKs. Your contract should require a dependency registry with licence types and update status.
This protects you from discovering post-handoff that a core library is GPL-licensed (with implications for proprietary code distribution), deprecated, or maintained by a single contributor who has gone quiet.
Define the handoff sprint contractually.
If you exit the relationship, the contract should specify a transition period, typically two to four weeks, where the outgoing team documents and walks a new team through the architecture. Some clients include a penalty clause for non-compliance. At minimum, the obligation should be explicit and tied to final payment.
For large engagements, consider code escrow. For projects above $200,000 or for mission-critical applications, a code escrow arrangement, where source code is held by a neutral third party and released under defined conditions such as vendor insolvency or material breach, provides protection that justifies the cost and administrative overhead.
Who Should Choose What: A Practical Decision Framework
Outsourcing decisions don’t have a single correct answer. They have conditions. Here’s how to frame the choice based on where you actually are.
Early-stage startup (pre-Series A, no internal Android team)
Outsourcing makes sense if your scope is defined well enough to be contracted.
- Run a discovery sprint before committing to a full build.
- Use a fixed-price or milestone-based T&M structure for your MVP.
- Keep the scope deliberately narrow, a working, performant core product is more valuable than a feature-complete but fragile one.
- Budget for post-launch support from the start; it’s far cheaper to structure it in the initial engagement than to renegotiate it after launch under pressure.
Growth-stage company (Series A–B, small internal team, scaling product)
A dedicated team often makes sense when Android development is ongoing and your roadmap extends 12+ months. The economics of a dedicated team at $8,000–$20,000/month compare favorably to the fully-loaded cost of a US mid-level Android hire.
Prioritise vendor consistency, team drift in dedicated models is the most common source of velocity decline over time. Make team composition change notification a contractual term.
Enterprise or established business building a new Android product line
Your primary risk isn’t cost, it’s integration complexity and compliance. Prioritise vendors with demonstrable experience in your industry’s compliance requirements (HIPAA for health, PCI-DSS for payments, GDPR for European users) and in Android’s enterprise management tooling (Android Enterprise, Managed Device Work Profiles).
Vetting should include a technical architecture review, not just a portfolio check or reference call.
If you’ve had a bad outsourcing experience before Conduct reference calls with at least two previous clients, not testimonials supplied by the vendor, but calls you arrange independently. Ask specifically about what went wrong and how the vendor handled it. Every engagement has friction. How a vendor responds to problems tells you more than how they perform when everything is smooth.
Conclusion
A well-outsourced Android app ships on time, performs consistently across the device fragmentation Android actually presents, and leaves you with a vendor relationship you can scale or exit cleanly. That outcome isn’t the default, it’s the result of the right engagement model, a contract that protects you after launch, and a partner who understands Android specifically rather than mobile generically.
The decisions that determine whether your engagement succeeds are almost all made before the first line of code is written: how you structure the discovery sprint, how thoroughly you scope the user flows, what your post-launch terms actually say, and whether the team who shows up for the work is the one who showed up for the pitch.
Get those things right, and the technical execution follows.
Unlock Your Telemedicine App’s Full Potential
We’ll tell you honestly whether outsourcing is the right move, which model fits your stage, and what a realistic scope looks like, before you’ve committed to anything. No pitch, no proposal until you want one.
Custom CMS Development: How to Plan, Build, and Avoid Costly Mistakes

A custom CMS is not always the right choice. For simple websites, CMS customization may be faster and more cost-effective.
But if your business needs unique content structures, advanced permissions, custom workflows, third-party integrations, stronger SEO control, or a backend your team can actually use, working with the right custom CMS development company becomes worth considering.
This guide explains what to plan, what it costs, and what to avoid.
How to Build A Custom CMS in 2026? Step-by-Step Process
A custom CMS should not start with code. It should start with the question your current CMS keeps creating:
Why does simple content work still need technical support?
Forrester predicted that web content management software is projected to reach $15.3 billion by 2028. CMS is no longer just a publishing tool. For growing businesses, it has become digital infrastructure.
1. Start With the Workflow, Not the Technology
Do not begin by asking whether the CMS should be built in Laravel, Node.js, .NET, React, or Next.js. That comes later.
Start by mapping how content actually moves through the business.
Ask:
- Who creates content?
- Who edits it?
- Who approves it?
- Who publishes it?
- Where does the current CMS slow the team down?
- Which users should only access specific fields or pages?
This matters because most CMS problems are not caused by a lack of features. They are caused by unclear workflows.
A marketing manager may need to update landing pages without touching layout code. A product team may need to manage feature pages. A compliance reviewer may only need approval access.
A developer may need control over templates and APIs, not daily publishing tasks.
2. Define Content Types and Publishing Rules
A custom CMS should not treat every page as a blank document. That is fine for a small website, but it breaks down when content becomes structured, repeatable, and tied to business outcomes.
Instead, define content types clearly.
| Content Type | Fields the CMS Should Support |
|---|---|
| Blog post | Author, category, slug, meta title, meta description, schema, featured image |
| Service page | Hero copy, CTA blocks, FAQs, testimonials, internal links, schema |
| Case study | Industry, challenge, solution, results, tech stack, project timeline |
| Location page | City, service area, local schema, localized CTA, map data |
| Product page | Features, pricing fields, media, FAQs, comparison blocks |
| Author profile | Bio, role, expertise, social links, related content |
This is where custom CMS solutions create real value. The system guides the team to publish consistent content instead of forcing every page to be rebuilt manually.
For SEO, this also protects structure. If every service page has fields for FAQs, schema, internal links, and metadata, optimization becomes part of the publishing process instead of an afterthought.
3. Design the Admin Experience
The backend is where most custom CMS projects either succeed or quietly fail.
A website can look polished on the front end, but if the admin panel is confusing, the business still has a CMS problem.
The admin experience should be built for the people who use it every week: marketers, editors, product managers, operations teams, and compliance reviewers.
A strong admin experience should include:
- Clean dashboard
- Simple content editor
- Preview mode
- Draft and publish controls
- Approval workflows
- Revision history
- Role-based access
- Media management
- SEO fields placed where editors actually need them
Here is the practical test: can a marketer update a headline, CTA, image, meta title, or landing page section without opening a development ticket?
If not, the CMS is still too dependent on engineering.
That does not mean giving everyone full control. A good custom CMS gives non-technical teams enough flexibility to move fast, while protecting templates, layouts, permissions, and critical fields from accidental damage.
4. Build the Core CMS Modules
Once workflows, content types, and admin UX are clear, then the development team can build the core modules.
For most custom CMS website development projects, the first version should include:
- User management
- Content management
- Media library
- SEO controls
- Navigation management
- Forms
- Search
- Permissions
- Reporting
- Audit logs
Do not overbuild the first version. This is where budgets get wasted.
The first version of a custom content management system should answer one question:
Can the team create, edit, approve, optimize, publish, and manage content safely?
If yes, launch the core system first. Advanced personalization, AI-assisted tagging, content recommendations, and automation can come later after real users start working inside the CMS.
This phased approach keeps the project practical and reduces the risk of building features nobody uses.
5. Connect Business Systems
A custom CMS becomes more valuable when it connects with the systems your business already depends on.
Common integrations include:
- CRM
- ERP
- Marketing automation
- Analytics
- Ecommerce systems
- Payment gateways
- DAM tools
- Internal databases
- Third-party APIs
This is where custom CMS development often makes more sense than basic CMS customization.
For example, a real estate platform may need property listings synced from an internal database. A healthcare website may need controlled approval workflows before content goes live. An ecommerce brand may need product content, campaign pages, inventory data, and customer segments connected across systems.
When these needs are handled through too many plugins, the CMS becomes harder to maintain. One plugin handles forms. Another controls SEO. Another manages redirects. Another connects analytics. Another handles schema. Over time, the backend becomes a dependency chain.
A custom CMS should simplify that environment by connecting systems through planned architecture, not patchwork fixes.
6. Test With Real Content Teams
Developers can test whether the CMS works. Content teams test whether the CMS is usable.
Before launch, give real users real tasks:
- Publish a blog post
- Update a service page
- Change a CTA
- Add SEO metadata
- Upload images
- Submit a page for approval
- Restore an older version
- Preview a page before publishing
Then watch where they slow down.
If users hesitate, the interface is unclear. If they keep asking developers for help, the workflow is wrong. If approvals still happen outside the CMS, the system has not replaced the old process. If SEO fields are skipped, they are probably hidden, confusing, or disconnected from the publishing flow.
This step is important because CMS adoption is not won in the architecture diagram. It is won in the daily publishing experience.
7. Launch, Train, and Maintain
A custom CMS launch is not finished when the website goes live.
The launch should include:
- Content migration
- QA testing
- Redirect validation
- SEO checks
- Analytics setup
- User training
- Documentation
- Backup setup
- Security monitoring
- Ongoing support
Training is not optional. If your team does not know how to publish, review, restore, optimize, and manage content inside the CMS, they will go back to old habits.
Maintenance also needs to be planned from the start. A custom CMS still needs security updates, performance monitoring, hosting support, bug fixes, and feature improvements as the business grows.
The best custom CMS is not the one with the longest feature list. It is the one your team can use confidently without turning every content update into a development task.
What Features Should a Custom CMS Include?
A custom CMS should include four layers: structured content management, SEO and marketing controls, workflow permissions, and enterprise safeguards. Build these first. Everything else is optional until your team proves they need it.
A good custom content management system should do the opposite: make daily publishing faster, keep technical risk under control, and stop content quality from depending on memory.
Essential CMS Features
The first layer is the publishing foundation:
| Feature | Build It This Way |
|---|---|
| Page management | Let users create approved page types, not random layouts |
| Custom content types | Give blogs, service pages, case studies, products, locations, and authors their own fields |
| Media library | Support alt text, file versions, compression, focal points, and CDN-ready assets |
| User roles | Control who can draft, edit, approve, publish, or delete |
| Drafts and revisions | Let users save work, compare versions, and roll back safely |
| Preview mode | Show the real page before it goes live |
| Scheduled publishing | Support campaigns, regions, and time-zone-aware launches |
| Search | Let teams find content by type, owner, status, date, or location |
The feature I would prioritize hardest is custom content types.
Blank editors feel flexible at first. Then every page starts looking different. One service page has FAQs, another does not. One location page has local schema, another misses it. One case study has results, another reads like a blog.
That is bad content architecture.
For a custom CMS website, structure should be built into the system. A service page should already have fields for hero copy, CTAs, FAQs, related case studies, internal links, trust signals, and schema. The editor fills the fields. The CMS protects the layout.
SEO and Marketing Features
SEO should be built into the CMS, not handled after publishing.
Include:
- Meta titles and descriptions
- Editable URLs
- Redirect management
- Canonical controls
- Schema fields
- XML sitemap logic
- Open Graph fields
- Internal linking fields
- Analytics and event tracking fields
Here is where implementation matters.
If a live URL changes, the CMS should warn the user and create a redirect. One careless URL edit can break rankings, backlinks, internal links, and paid campaign pages.
Do not make editors paste schema code. Build structured fields that generate schema from FAQs, authors, services, products, reviews, or local pages.
Do not hide SEO controls in a settings tab nobody opens. Put metadata, canonical options, Open Graph previews, and internal link suggestions inside the publishing workflow.
The lesson is not “use Sanity.” The lesson is that CMS features should connect directly to publishing velocity, SEO output, and team ownership.
Workflow and Permission Features
Once more than one team uses the CMS, simple “admin” and “editor” roles are not enough.
Build:
- Admin, editor, author, and reviewer roles
- Approval stages
- Content locking
- Audit logs
- Department-level access
- Multi-site or multi-location permissions
This is where a custom CMS becomes safer than basic CMS customization.
Enterprise Features
Enterprise features are not “nice to have” when the CMS supports multiple teams, sensitive workflows, integrations, or high-traffic pages.
Build early for:
- SSO
- MFA
- API access
- Webhooks
- Backups
- Security logs
- Compliance support
- Scalable hosting
- Multi-language support
SSO and MFA protect access. API access lets the CMS serve websites, apps, portals, ecommerce platforms, and internal tools. Webhooks can trigger cache clearing, search indexing, translation workflows, frontend rebuilds, or approval notifications.
Backups should be tested, not assumed. A backup that has never been restored is not a recovery plan.
Security logs also deserve real attention. IBM’s Data Breach Report puts the global average breach cost at $4.4 million, which is why CMS access, permissions, and audit trails should be treated as risk controls, not backend extras.
Also read: Best Enterprise CMS platforms
Custom CMS Architecture: What Should Be Built?
A custom CMS architecture should not be planned around screens first. It should be planned around how content will be stored, reused, delivered, secured, and changed later.
This is where the build either becomes scalable or expensive to maintain.
The main decision is whether the CMS should be monolithic, headless, or hybrid.
| Architecture Type | Best For | Risk |
|---|---|---|
| Monolithic CMS | Simple websites where backend and frontend can stay together | Harder to reuse content across apps, portals, or multiple frontends |
| Headless CMS | Websites, apps, portals, and multi-channel content delivery | Requires stronger frontend and API planning |
| Hybrid CMS | Businesses that need editorial control plus flexible content delivery | Can become complex if roles and APIs are not clearly defined |
For most growing businesses, a hybrid or API-first custom CMS works best. It keeps the admin experience simple for content teams while giving developers clean APIs for websites, apps, ecommerce systems, or customer portals.
The second decision is content modeling. The CMS should not store content as static pages only. It should store reusable business objects: services, authors, case studies, products, locations, FAQs, media, and categories. That makes content easier to reuse across landing pages, blogs, apps, and regional websites.
The third decision is system boundaries. Business logic, permissions, validation, and integrations should live in the backend, not inside the admin screen. The frontend should display content. The CMS should structure and govern it. APIs should move it safely.
That separation matters because designs change, campaigns change, and integrations change. If everything is tightly coupled, every change becomes a rebuild.
How Much Does Custom CMS Development Cost?
Custom CMS development usually costs $15,000 to $300,000+, depending on whether you are building a simple internal CMS, a custom CMS website, or an enterprise-grade content platform with integrations, workflows, migration, security, and multi-channel delivery. Public CMS pricing guides place mid-range custom CMS projects around $10,000–$120,000 and enterprise builds around $120,000–$300,000+, so these ranges are realistic planning benchmarks, not fixed quotes.
Custom CMS Development Cost by Project Type
| CMS Type | Estimated Cost | What You Usually Get |
|---|---|---|
| Basic custom CMS | $15,000–$40,000 | Admin panel, page/content management, media uploads, basic roles, SEO fields |
| Mid-level custom CMS website | $40,000–$120,000 | Custom content types, approval workflows, SEO controls, integrations, migration, reporting |
| Enterprise custom CMS solution | $120,000–$300,000+ | Advanced permissions, multi-site support, APIs, SSO/MFA, localization, DevOps, security controls |
| Complex CMS with advanced integrations | $300,000+ | Multi-brand or multi-region CMS, ecommerce/CRM/ERP/DAM integrations, custom workflows, high-scale infrastructure |
I would not recommend building a custom CMS under the assumption that “we only need a backend.” That is how projects get underquoted. The backend is only one part. The expensive work is usually in the decisions: how content is modeled, how users are allowed to change it, how existing content is migrated, how integrations behave, and how the system stays stable after launch.
Custom CMS Development Cost by Region
| Region | Typical Hourly Range | Best Fit |
|---|---|---|
| North America | $80–$200/hr | Enterprise strategy, regulated industries, complex architecture |
| Western Europe | $70–$150/hr | Strong engineering, compliance-heavy projects, enterprise builds |
| Eastern Europe | $35–$70/hr | Strong technical delivery with moderate cost |
| Latin America | $30–$60/hr | Nearshore teams, US time-zone overlap, agile delivery |
| South Asia / Southeast Asia | $25–$50/hr | Cost-efficient builds when project management is strong |
What Affects the Custom CMS Development Cost?
The cost of custom CMS development rises when the CMS has to support more business logic, more users, more content relationships, or more systems. The biggest cost drivers are:
| Cost Driver | Why It Increases Budget |
|---|---|
| Number of content types | Each content type needs fields, validation, templates, permissions, and testing |
| Design complexity | Flexible page sections and custom layouts require more frontend and CMS logic |
| User roles | More roles mean more permission rules and edge cases |
| Approval workflows | Review, compliance, and publishing flows require careful backend logic |
| Integrations | CRM, ERP, ecommerce, DAM, analytics, and APIs add planning and testing time |
| Migration scope | Existing pages, metadata, media, redirects, and URLs must be preserved |
| Security requirements | SSO, MFA, audit logs, encryption, and compliance controls increase effort |
| SEO requirements | Schema, redirects, canonicals, sitemaps, and metadata need CMS-level planning |
| Hosting and DevOps | Staging, deployment, backups, CDN, monitoring, and scaling add cost |
| Ongoing maintenance | Bugs, updates, support, and new features need post-launch budget |
Hidden Costs to Plan For
The most expensive CMS costs are often the ones nobody includes in the first estimate.
Plan for these early:
- Content migration
- SEO migration
- Redirect mapping
- QA testing
- Documentation
- User training
- Hosting
- Maintenance
- Security updates
- Future feature requests
The best way to control cost is not to choose the cheapest team. It is to define the first version properly. Build the content models, workflows, SEO controls, permissions, and integrations that matter now.
Leave advanced automation, personalization, and AI-assisted features for later unless they solve a current business problem.
Custom CMS vs WordPress vs Headless CMS
If your website is simple, WordPress may be enough. If your content needs to publish across websites, apps, and portals, headless CMS may fit better. If your workflows, permissions, integrations, or business rules are too specific for a prebuilt platform, custom CMS development is the stronger choice.
| Factor | Custom CMS | WordPress | Headless CMS |
|---|---|---|---|
| Best for | Complex workflows | Standard websites | Multi-channel content |
| Flexibility | High | Medium | High |
| Launch speed | Slower | Faster | Medium |
| Cost | Higher upfront | Lower upfront | Medium to high |
| Security control | High | Plugin-dependent | High |
| Editorial ease | Built around your team | Familiar interface | Depends on setup |
| Integrations | Fully custom | Plugin/API-based | API-first |
| Scalability | High if built well | Depends on setup | High |
What are the Common Custom CMS Development Mistakes?
The most common custom CMS development mistakes are building the CMS for developers instead of content teams, overbuilding the first version, ignoring SEO during development, planning migration too late, and launching without a maintenance plan.
1. Building for Developers Instead of Editors
This is the mistake I would watch first.
A CMS can be technically clean and still fail if marketers, editors, and product teams avoid using it. You see it in small details:
- Field names only developers understand
- Too many required fields
- No clear preview mode
- Confusing media controls
- No simple way to edit CTAs, metadata, or page sections
- Marketers still asking developers for routine updates
That is a bad sign. A custom CMS should reduce dependency on engineering, not create a prettier way to submit developer requests.
2. Overbuilding the First Version
A custom CMS does not need every possible feature in version one. That creates three problems:
- Longer development timelines
- Higher upfront cost
- Poor adoption because the CMS feels heavy from day one
A good custom CMS starts focused. It can grow later.
3. Ignoring SEO During Development
SEO should not be added after the CMS is built. By then, the wrong URL logic, metadata structure, sitemap rules, and page templates may already be baked into the system.
The most common SEO mistakes include:
- Broken URLs
- Missing redirects
- Weak metadata controls
- No canonical settings
- No schema support
- Poor XML sitemap logic
- Slow page templates
- Image-heavy pages without optimization
- No control over index/noindex settings
This is especially risky during custom CMS website development because the CMS controls how pages are created, structured, and published.
4. Poor Migration Planning
Migration is often underestimated because it sounds simple: move old content into the new CMS. Common migration problems include:
- Lost metadata
- Broken internal links
- Missing media files
- Duplicate pages
- Changed URLs without redirects
- Poorly formatted content
- Missing schema
- Broken author or category relationships
Do not treat migration as data entry. Treat it as SEO and content risk management.
5. No Maintenance Plan
A custom CMS is not finished when it goes live.
Without maintenance, the system slowly becomes harder to use and more expensive to fix. The common issues are:
- Security risks
- Outdated dependencies
- Performance problems
- Broken integrations
- Growing feature backlog
- Weak post-launch support
- No clear owner for future improvements
This is where custom CMS solutions succeed or fail long-term. The launch proves the CMS works. Maintenance proves it can keep working as the business grows.
Custom CMS Development Checklist (2026)
Use this custom CMS development checklist before planning, building, or launching the system.
Strategy Checklist
- Business case is clear
- CMS users are identified
- Current CMS problems are documented
- Content types are mapped
- Approval workflows are defined
- Integration needs are listed
- Budget range is approved
This is the first filter. If the business cannot explain why it needs a custom CMS, the build will likely become expensive and unfocused.
Architecture Checklist
- Admin panel is planned
- Content model is defined
- Database structure is mapped
- API layer is planned
- Frontend delivery is confirmed
- Security controls are included
- Hosting strategy is selected
This is where the CMS becomes scalable or fragile. The content model should be clear before development starts.
SEO Checklist
- URL structure is preserved
- Redirect map is prepared
- Metadata fields are included
- Canonical controls are added
- Sitemap logic is planned
- Schema fields are supported
- Page speed is tested
This checklist protects organic visibility. A custom CMS website should not go live until URLs, redirects, metadata, schema, canonicals, and sitemap logic are tested.
Launch Checklist
- Content migration is tested
- QA is complete
- User roles are configured
- Training documents are ready
- Analytics is installed
- Backups are enabled
- Support plan is confirmed
The launch is not just a deployment. It is the moment your content team starts using the CMS under real pressure.
Build a Custom CMS Your Team Can Actually Use
Planning a custom CMS website but not sure what features, workflows, or architecture you really need?
Get a Free CMS Consultation

