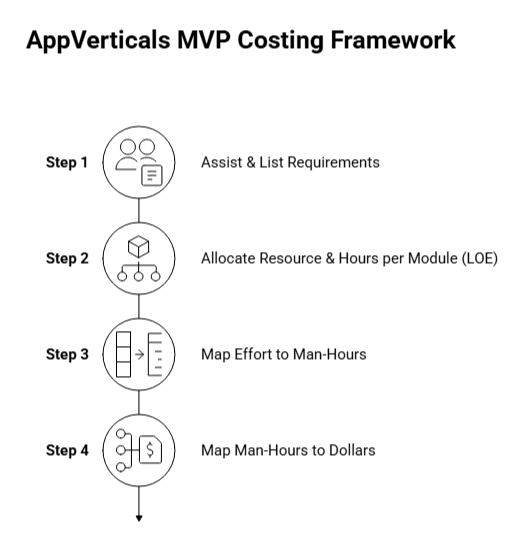















To choose the right MVP development service for your startup, look for a partner who starts with discovery before scoping, defines clear boundaries around what version one will and will not include, and can demonstrate working software at regular intervals throughout the build, not just at the end.
That answer sounds simple. In practice, most founders get it wrong, not because they chose an incompetent team, but because no one drew a hard boundary around what the MVP was supposed to prove. The result is a familiar pattern: a focused idea becomes a long feature list, the budget expands sprint by sprint, and months later the founding team cannot answer a basic question: what exactly is version one supposed to demonstrate?
The sections below draw on AppVertical’s real engagement with a freight-tech startup that contacted our team after spending nearly two years building with another agency, and still having nothing ready to ship. They show, in detail, what that kind of product failure actually looks like, and what a structured MVP process truly requires.
Key Takeaways
The Freight-Tech Rescue by AppVerticals: A Reference Case for Choosing the Right MVP Development Service
A freight-tech startup came to us after almost two years with a prior agency. On discussion, we realized that the client needed an MVP developed for their product idea and it had been two years of working with the agency but with no significant or expected success on the project.
Clearly, the client and the agency had not planned the MVP effectively.
After a decade of working with startups and enterprises, we’ve seen this happen repeatedly when there is a lack of clarity around what the product actually requires and how to scope an MVP properly. Without that structure, projects often miss launch timelines and fail to achieve the MVP’s core purpose: gathering real market feedback to guide the next phase of development.
The client shared that while their original brief was focused, over time, the scope had expanded without a formal change-order process, the budget had grown without a clear justification trail, and communication between the client and agency had become inconsistent. All of which resulted in a delayed and expensive product that was all over the place and definitely not ready for launch to market.
By the time they reached us, the product had ballooned into a long feature list with no clean answer to the most basic product question: who is the first user, and what does this version need to prove for them?
The developers at the prior agency were not incompetent. The agency was not obviously dishonest. The build failed because nobody had ever stopped to define what the MVP actually needed to prove, who it was being built for, or what “done” looked like for version one.
The best way forward was a reset. A reset that did not mean more development. We began by stopping the build entirely, re-running discovery, mapping what existed, identifying the core user journey, and cutting everything that did not support that journey. Within the first sprint after that reset, the client had a working, tested module they had not seen in nearly two years. That is the difference between motion and progress.
Every lesson in this guide comes from what this partnership with the freight-tech startup exposed, about scoping, about discovery, about QA, and about what a clean handoff actually requires.
Below we will discuss the exact method to vet and choose the right MVP development service provider for your startup. Feel free to make notes as you go along.
First, Be Honest About What Stage You Are Actually In
Before you speak with a single freelancer or agency, answer this without startup theater: what does success look like for this MVP in operational terms? Not “raise our next round.” Not “digitize the industry.” Not “build the future of logistics.” What is the one core user action this product must enable, and what evidence would tell you it is working?
Founders who cannot answer that question usually ask agencies for the wrong thing. They ask for a platform when they need a test. They ask for a complete feature roadmap when they need one working user journey. They ask for a fixed quote before they have fixed the problem they are solving.
That is why discovery matters. An MVP is not the smallest amount of software you can release. It is the smallest amount of software that helps you learn something important fast enough to matter. If you are unsure how to structure that learning loop, here is how to build an MVP the right way.
Another important thing that founders may miss is identifying whether MVP is the right choice for development in the current phase. Sometimes, MVP is too early for the specific project and the best next step is simply a prototype or a Proof-of-Concept (POC). Other times, a bare MVP may not fulfill the purpose and an MLP is required. Further, and this may come as a surprise, directly heading for a full development is also the right choice in some cases. In which case, investing in an MVP is unnecessary and expensive. If you are sure of MVP, read on!
Otherwise, read poc vs prototype vs MVP blog to know which stage you fall in or read MVP vs Full Product, if you want to read about later stages and when to head directly to a full product development.
In case you’d like to speak to experts in our team for a free consultation, that’s also available. Click here to book a call.
Freelancer or MVP Development Service? The Honest Answer Depends on Stage, Coordination Load, and Handoff Risk
A freelancer can be the right choice when the scope is narrow, the risk of rework is low, and someone on the founding team can actively manage the work. An MVP development service becomes more valuable when the real problem is not just execution, but orchestration: product thinking, design clarity, QA discipline, communication rhythm, and a handoff that survives the original builder.
| Stage | Freelancer Works When | MVP Development Service Makes Sense When |
|---|---|---|
| Pre-seed | The scope is one primary user flow, the goal is a demo or market test, and a founder can manage the moving pieces. | You need design, development, and QA together and nobody on the team has time or experience to coordinate them. |
| Seed | You have a technical co-founder who can own architecture, code review, and future hiring. | The codebase must survive beyond the original builder, and clean process matters as much as velocity. |
| Series A or internal new product line | Rarely the best fit unless the freelancer is integrating into a mature product org with strong internal leadership. | Usually the right call when stack alignment, reporting cadence, security expectations, and team integration all need structure. |
If your MVP is mobile-first, this decision gets more specific: you are not just choosing between a freelancer and an agency, but between a generalist build partner and a mobile app development company with the platform expertise to match.
When Exploring Different MVP Development Vendor Services: What Separates A Strong Partner From One That Just Executes?
Most agencies can write code. Fewer can scope a product, manage a build, and hand it off in a state that survives the original team. Below is not about what a standard process looks like, it is about what the best MVP development services for startups do differently at each stage of the engagement, and what the freight-tech case exposed when those things were absent.
1. Discovery That Draws the Line on Version One
A credible engagement starts by identifying the hypothesis, the user, the success condition, and the edges of version one. This should produce a scoped brief with explicit exclusions, not a fuzzy summary of what might be built.
That is precisely what happened in the freight-tech case: two years of building the product right, while the question of what the right product actually was had never been properly answered.
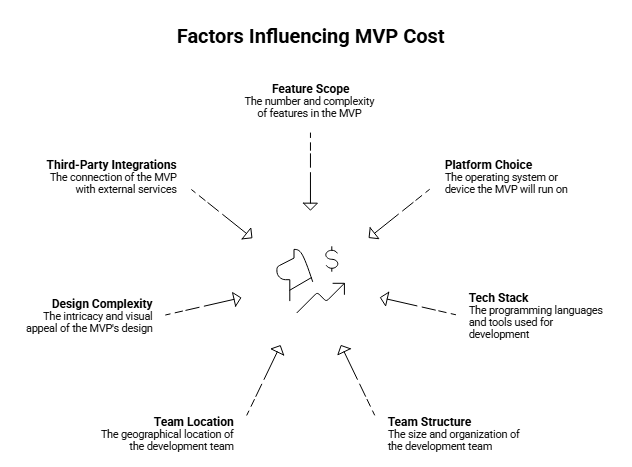
That rework has a real price, here is what MVP development cost actually looks like when scope is managed well versus when it isn’t.
2. Wireframes That Prevent Interpretive Development
Wireframes are not cosmetic. They reduce guesswork. When founders say “we thought that screen would work differently,” what they usually mean is that the team started building before the information architecture was agreed. A proper wireframe pass keeps feature discussions concrete and stops product decisions from being made accidentally inside development tickets.
3. Sprint Reviews with Working Software, Not Status Theater
You should see testable modules during the build, not a dramatic reveal at the end. If a partner cannot show working increments, you do not actually know whether progress exists or whether tasks are simply moving from “in progress” to “almost done.”
Founders get trapped here because effort looks like momentum, until the final weeks expose what never really worked.
4. QA as a System, Not a Promise
“We test as we go” is not a QA strategy. Structured QA means defined test cases, visible acceptance criteria, written defects, and clarity about what is known to be unfinished. MVP does not mean sloppy. It means selective. A narrow scope and professional quality inside that scope are not in conflict.
5. A Handoff That Makes Future Hiring Possible
Repository access, deployment instructions, environment variables, third-party credentials, architecture notes, and a record of known issues should all be part of closeout. If your next developer needs three weeks of archaeology just to understand the setup, the product may be live, but the handoff failed.
Meeting the Vendors: What to Ask on Every Discovery Call You Make
Most founders walk into agency calls underprepared and leave impressed by confidence rather than process. The questions below are designed to reverse that. They are not random questions, they are process questions, and a partner who has done this well will answer them without hesitation. A partner who hasn’t will reveal that quickly too.
Use these during every call. The gap between strong and weak answers is where your real evaluation happens.
| Question | Strong Answer | Weak Answer |
|---|---|---|
| Can you walk me through your discovery process? | Named outputs: user-flow mapping, requirements brief, feature prioritization, assumptions, exclusions, and acceptance criteria. | “We will gather what we need once the project starts.” |
| Who exactly will work on my project? | Named people and clearly defined roles. | Staffing based on availability. |
| How do you handle scope changes mid-project? | A documented change-order process with written approvals and clear impact on timeline or budget. | “We are flexible.” |
| What do I see during the build? | Working modules, demo cadence, staging access, and a defined sign-off process. | Progress summaries with no testable software. |
| What AI tooling do you actually use in development? | Clear explanation of where tools like Cursor, v0, Bolt, Lovable, or GitHub Copilot accelerate delivery, and where senior engineering judgment still drives decisions. | Generic claims like “we use AI for everything” with no process clarity. |
| Where does AI stop and human expertise take over? | Specific examples around architecture, security, discovery, acceptance criteria, scalability, and QA requiring senior oversight. | “AI handles most of the development now.” |
| How do you verify AI-generated code? | Human code reviews, QA testing, security checks, and documented validation workflows. | Blind trust in AI-generated output. |
| What is included in the handoff? | Repository transfer, deployment documentation, credential transfer, QA notes, and a defined support window. | Vague assurances that you will be “all set.” |
How AI Tooling Fits Into This Evaluation
Founders should absolutely ask agencies how they use tools like Cursor, v0, Bolt, Lovable, and similar AI-assisted workflows. But the better question is not “Do you use AI? it is “Where does AI materially reduce time, and where do you still rely on senior human judgment?”
McKinsey has reported substantial speed gains for common developer tasks, code documentation in roughly half the time, writing new code in nearly half the time, and refactoring in nearly two-thirds the time, while also warning that the gains shrink on complex tasks and can even reverse for inexperienced developers.
Google’s 2025 DORA research similarly found broad adoption and strong self-reported productivity gains, while emphasizing that AI works best as a supportive tool rather than a replacement for judgment, process, or trust.
Faique Ali, Lead AI Engineer at AppVerticals, puts it plainly from experience working across both AI-assisted and traditional workflows:
That is the standard to hold any agency to. If they cannot explain where AI saves time and where it stops, they are either not using it thoughtfully or not being straight with you about how the work gets done.
Why Ask About Post-Launch Support At This Point
Most founders evaluate partners on proposals and how convincing the sales call feels. The harder test comes after launch. Add these to your discovery call checklist:
This is where many founders learn too late that a live product is not the same thing as an operable product. If only the original team knows how to deploy it, debug it, or change it safely, you do not own a product yet. You rent access to one.
Discovery Call Checklist: Seven Signs You Are Talking to the Right MVP Partner, and the Red Flags That Tell You to Leave
Proposals look polished. Sales calls feel confident. Neither tells you much about how a partner actually works once the contract is signed and the pressure is on. These seven signals cut through the presentation layer, they are about process, accountability, and how a partner behaves before you have committed anything. One or two red flags may be recoverable. Several in the same call is a pattern, not a coincidence.
They run a structured intake before scoping.
• Red flag: proposals that promise a “complete platform” without a hard feature boundary.
They define what version one will not include.
• Red flag: proposals that promise a “complete platform” without a hard feature boundary.
They ask about the current workaround.
• Red flag: they jump straight to technology before understanding the behavior they are trying to change.
They assign named roles up front.
• Red flag: a faceless “senior team” that changes after contract signature.
They show you the communication structure, not just good intentions.
• Red flag: “We are very responsive” with no operating rhythm behind it.
They plan to demo working modules during the build.
• Red flag: “We will show you everything once the development phase is complete.”
They explain the handoff before you sign.
• Red flag: “We will walk you through all of that later.”
Conclusion: The Real Decision Founders Are Making
Choosing an MVP development service is not mainly a vendor selection exercise. It is a decision about how much uncertainty you are willing to carry into the build.
The freight-tech engagement is the clearest possible illustration of what happens when that uncertainty is left unresolved. Bad engagements do not begin with bad code. They begin with vague goals, soft boundaries, and the hope that execution will create clarity later.
Founders who avoid the freight-tech trap do three things well. They get honest about the stage they are in. They ask sharper questions in discovery. And they judge partners not by how confidently they promise delivery, but by how rigorously they control scope, communication, QA, and handoff.
That is how you avoid spending two years building and still having nothing to ship.
No Proposal Until the Product Scope Is Clear
We built this guide because we have seen what happens when the brief is wrong. If you are evaluating MVP development services for your startup, start with a 30-minute call, no pitch, no pricing until we understand what you are actually building and why.
Related Guides
- MVP in Software Development: Learn what MVP actually means in a software context, how it differs from a prototype or beta, and why getting that definition wrong is where most builds go sideways.
- MVP vs Full Product: A practical breakdown of where an MVP ends and a full product begins, and how to know which one you are actually ready to build.