
About Us
About Us
We’re a future-focused tech partner working with some of the world’s top enterprises. At AppVerticals, we design solutions that drive growth and reimagine digital experiences.

Services
Software Development
Mobile App Development
Web Design & Development
Tell us what you're looking for, and we'll tailor a solution based on your business needs.
Talk to Experts
Health Tech

EdTech

Logistics
Real Estate

Ecommerce

Sports
Fintech
Travel

Restaurant

Automotive
HIPAA-compliant digital solutions for hospitals, clinics, and healthtech startups driving better patient outcomes.
What we do:
Scalable learning platforms for schools, universities, and EdTech startups transforming education delivery.
What we do:
Real-time tracking and automation solutions for freight companies, warehouses, and delivery services.
What we do:
PropTech platforms for brokerages, property managers, and real estate marketplaces are streamlining operations.
What we do:
High-converting commerce platforms for D2C brands, retailers, and online marketplaces are driving revenue growth.
What we do:
Fan engagement platforms for sports teams, leagues, and betting operators are creating immersive experiences.
What we do:
PCI-DSS compliant solutions for digital banks, payment platforms, and InsurTech companies, ensuring security.
What we do:
Booking and hospitality solutions for OTAs, hotels, and tourism platforms, enhancing traveler experiences.
What we do:
Online ordering and operations software for restaurants, cloud kitchens, and food delivery platforms.
What we do: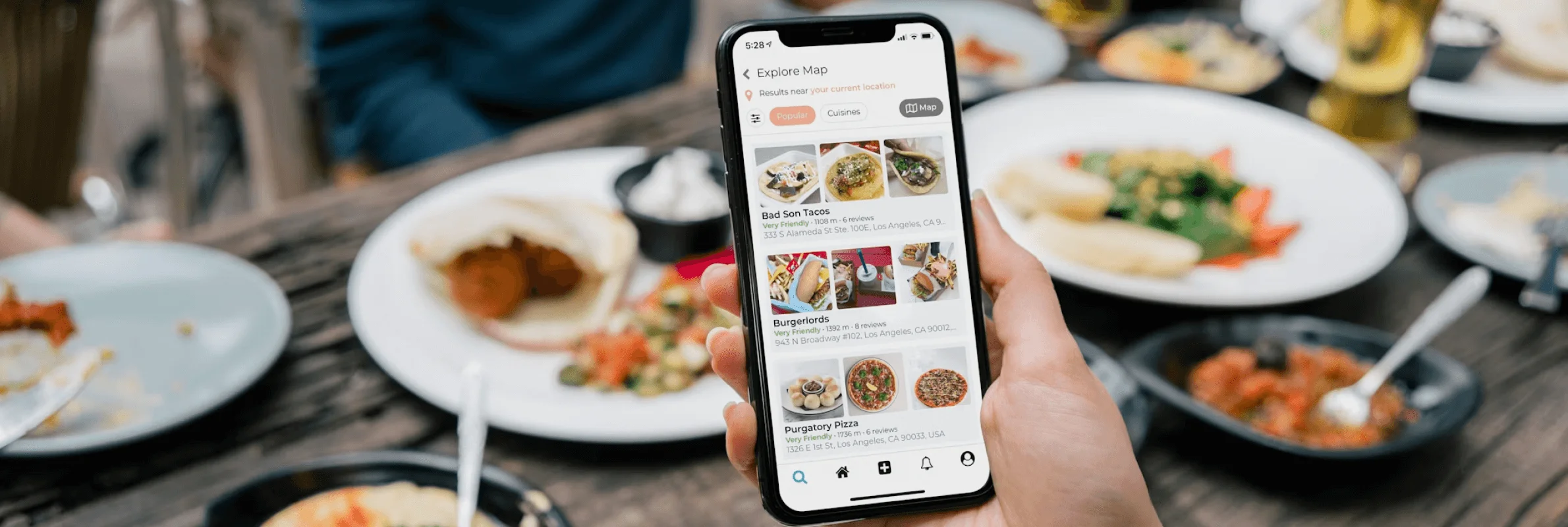
Connected vehicle platforms for automotive OEMs, dealerships, and mobility providers are accelerating innovation.
What we do:
Our Odoo implementation brings financial discipline, operational visibility, and process control across departments. From accounting automation to manufacturing workflows, we design ERP systems that reduce operational leakage and provide real-time decision clarity.
We use Sitecore to drive measurable revenue growth through intelligent personalization and behavior-driven content delivery. By aligning marketing automation, data orchestration, and omnichannel engagement, we help brands turn digital touchpoints into retention engines.
We architect AWS environments that stay stable under scale, traffic spikes, and compliance pressure. From secure cloud migrations to CI/CD automation and cost governance, we engineer cloud foundations that protect performance while enabling rapid product evolution.
We implement Dynamics 365 to align systems with actual business operations, bringing clarity, control, and accountability across CRM, ERP, and service functions. From sales to finance, configurations eliminate inefficiencies and enable confident, real-time decisions.
Tell us what you're looking for, and we'll tailor a solution based on your business needs.
Talk to ExpertsPortfolio

AppVerticals was featured in Inc. 5000 as
America’s Fastest Growing Tech Company
See what it might cost to bring your app idea to life. Our calculator gives you a quick, simple estimate based on what you need.
 verified expert
verified expert
Senior Writer and Editor - App, AI, and Software
Muhammad Adnan is a Senior Writer and Editor at AppVerticals, specializing in apps, AI, software, and EdTech, with work featured on DZone, BuiltIn, CEO Magazine, HackerNoon, and other leading tech publications. Over the past 6...
See Full Bio19 minutes read
In 2026, AI in EdTech delivers value when models are allowed to override static curricula, like skipping, repeating, or reordering learning paths based on failure patterns. Teams that limit AI to recommendations or content generation rarely see measurable impact beyond experimentation.
EdTech companies are using AI in production to make three decisions that directly move learning outcomes and revenue: what a learner sees next, when an assessment adapts, and when intervention is triggered.
I’ve seen the difference, like teams get ROI when AI is wired into progression + assessment logic, not bolted on as “features.”
The spend is following that reality: the AI in education market is projected to grow $32.27B by 2030, ~31.2% CAGR.
As an edtech app development company, this is the layer we evaluate first.
AI in EdTech delivers ROI only when it controls progression, assessment adaptation, and intervention timing, not when it’s limited to recommendations or content generation.
Adaptive learning and assessment automation are the highest-impact use cases, with engagement and completion gains of 20–40% when tied to mastery signals.
Most failures are execution failures, caused by weak data pipelines, lack of monitoring, early overengineering, and ignoring governance until scale.
Hybrid AI architectures outperform pure LLM stacks, using traditional ML for high-frequency decisions and LLMs selectively for feedback and content.
Education app development cost rises at production scale due to integration, compliance, and monitoring, with realistic AI budgets ranging from $60k to $1M+.
AppVerticals helps EdTech teams move AI from experimentation to production, leveraging deep EdTech delivery experience across 200+ education solutions serving 20M+ learners.
They’re using AI to make high-leverage product decisions inside the learning flow, like personalization, assessment/feedback, and content operations, because those are the only places AI reliably moves outcomes at scale.
A quick reality check from what I see in real deployments: “AI features” don’t create the lift. Decision automation does, especially when it’s tied to progression rules, mastery thresholds, and intervention triggers (not just recommendations).
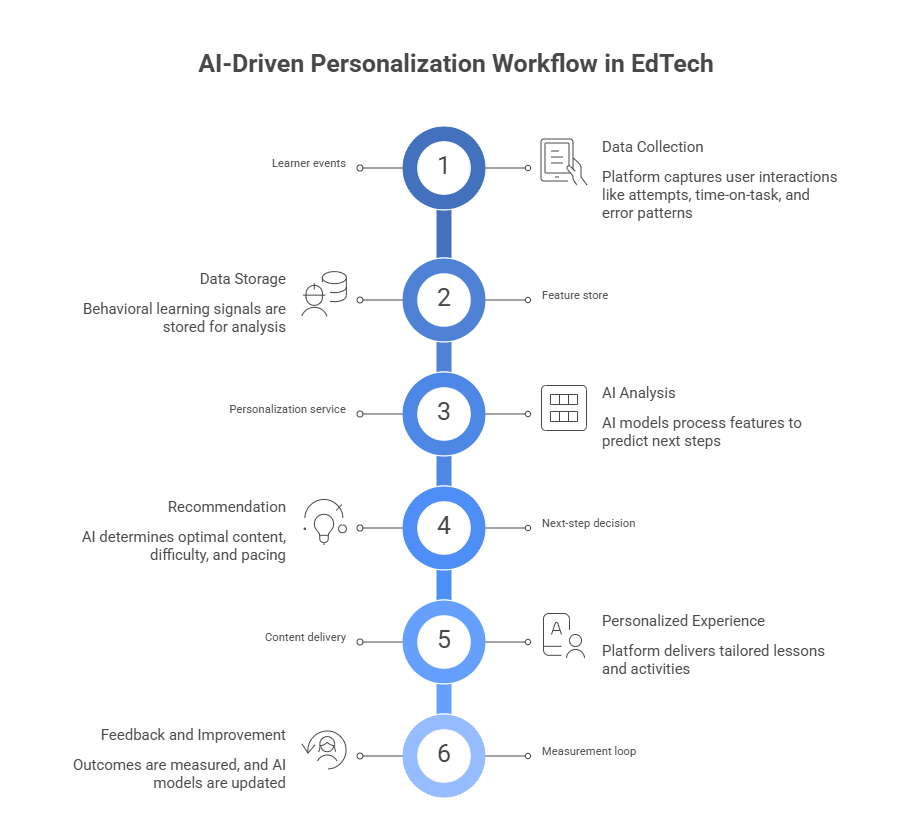
It works by using behavioral learning signals (not demographics) to decide what content comes next, how difficulty adjusts, and when the platform should slow down or accelerate.
AI-driven personalized learning systems have been shown to increase student engagement and retention by up to ~30% by adapting lessons to learner performance in real time. It is an evidence that production-grade decision automation (not superficial features) changes core learning outcomes.
Furthermore, An EDUCAUSE survey of more than 800 higher-education institutions found 57% are prioritizing AI implementation in 2025, up from 49% in the prior year, signaling that successful organizations are integrating AI into core workflows rather than treating it as an experiment.
In multi-region platforms, the personalization stack that holds up in production usually looks like this:
Diagram (what actually runs in production):
A systematic review of recent studies confirms that personalized AI models can significantly enhance student engagement and tailored learning experiences, demonstrating measurable benefits across diverse contexts.
What’s “real” about this is the feedback loop: personalization systems only improve when they’re continuously evaluated against outcomes (completion, mastery, retention), not just click-through.
They’re using AI to compress the feedback cycle, like auto-grouping, rubric-based scoring support, and faster iteration on misconceptions, so instructors spend time on judgment, not clerical grading.
For many teams, this directly addresses one of the most persistent education app development challenges, such as scaling assessment and feedback without increasing instructor workload or compromising trust.
Recent reviews highlight that AI tools in education are increasingly linked to personalized instruction and enhanced learning outcomes, specifically in adaptive testing and feedback. A pattern seen across higher education and professional upskilling environments.
Workflow (how it’s typically deployed without breaking trust):
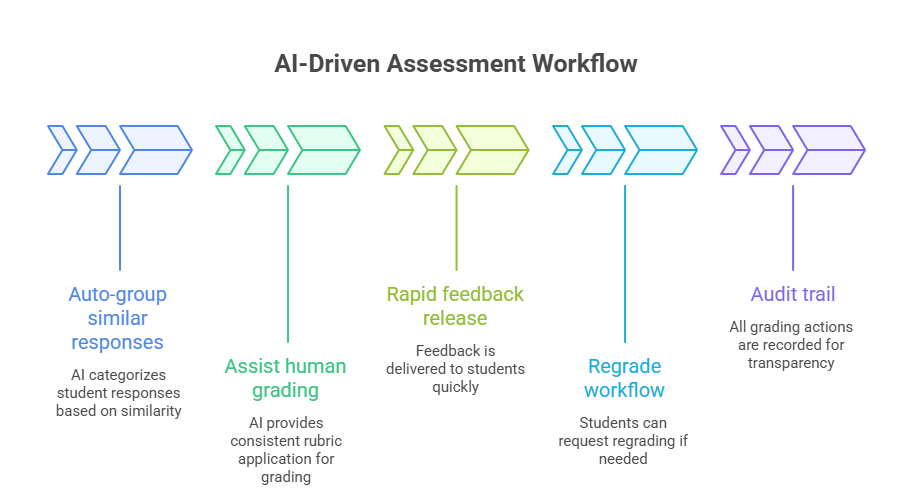
Teams that get adoption don’t oversell “auto-grading.” They position it as speed + consistency + auditability, with human override baked in, because credibility is the product in EdTech.
It improves productivity when it’s used for structured drafts, variants, and alignment work (objectives, rubrics, question banks), not when it’s asked to invent pedagogy from scratch.
While generative productivity results vary by implementation, broader AI productivity research shows that AI adoption can increase productivity outcomes and task completion speed across knowledge work by substantial margins.
What “good” looks like in production content ops:
The key pattern I see: the wins come from reducing latency in content operations, not “AI-generated courses.” Production teams treat AI as an accelerator inside a governed workflow.
The AI use cases that actually move financial and learning metrics are those that optimize learner flows, reduce friction, and automate predictable decisions.
A study from McKinsey finds that personalized learning implementations can improve engagement by 20–40% and lift completion metrics as well.
Below we break down what actually works, what looks good but doesn’t scale, and how leaders decide where to invest next.
Adaptive sequencing and mastery-based adjustments are the AI features most consistently tied to improved retention and engagement.
Platforms that permit the system to reprioritize content based on mastery signals, show measurable effects on learner behavior.
In third-party evaluations, students using DreamBox’s adaptive learning model showed measurable gains in engagement and achievement, particularly when usage crossed defined weekly thresholds.
In practice this means:
These systems go beyond “recommendations” and become part of a closed-loop learning engine, which is where the measurable engagement lifts come from.
Standalone conversational tutors and generic AI assistants often fail to move engagement because they don’t change core decision points in learning workflows.
Common failure modes include:
These kinds of “impressive but inert” features can create FOMO but rarely deliver measurable business or learning outcomes at scale.
EdTech leaders prioritize AI initiatives based on impact vs. implementation risk, with clear signals on retention, cost savings, or operational leverage.
In Series B or later startups, the AI roadmap often looks like:
A useful real-world signal comes from Duolingo’s public disclosures. In 2025, the company shared that AI tooling allowed it to launch over 140 new courses in roughly a year, compared to more than a decade to reach its first 100 courses.
The AI investment paid off not because it improved “conversation,” but because it collapsed content production timelines, a direct operational ROI.
So, making an app like duolingo, can be significant for the relevant audience.
Practical guidelines leaders use:
The goal is to fund what moves the needle on KPIs your board and customers actually care about, not just the glossy demos.
A hybrid architecture works best: use traditional ML for high-volume decisions (scoring, routing, risk), and LLMs only where language adds value (explanations, feedback, content transforms).
The practical reason is cost + latency control: LLM calls are metered per token, so you don’t want your core “every click” pathway to depend on them. OpenAI’s published API pricing makes the unit economics explicit (priced per 1M tokens and model tier).
Hybrid wins for most scalable EdTech products: ML runs the decision engine; LLMs handle language and edge cases.
Decision table (what to use where):
| Need | Best Fit | Why It Holds Up in Production |
|---|---|---|
| Next-step progression, mastery scoring, churn risk, intervention triggers | Traditional ML | Fast, cheap per call, consistent, easier to test |
| Feedback phrasing, explanations, rubric-aligned comments, content rewriting | LLMs | Language quality and adaptability |
| Assessment pipelines (detect misconception and generate feedback) | Hybrid | ML detects and flags; LLM drafts; human and guardrails approve |
Rule I use in real builds: if the model runs on every learner event, it should be ML-first; if it runs on selected moments (feedback, explanation), LLMs are justified, especially when you can cache or batch calls using the pricing levers providers publish.
Design pipelines so training and serving data stay consistent, and so you can monitor drift and retrain without rewriting the product.
McKinsey notes that 70% of top performers experienced difficulties integrating data into AI models (data quality, governance processes, training data).
Stack diagram (production-friendly):
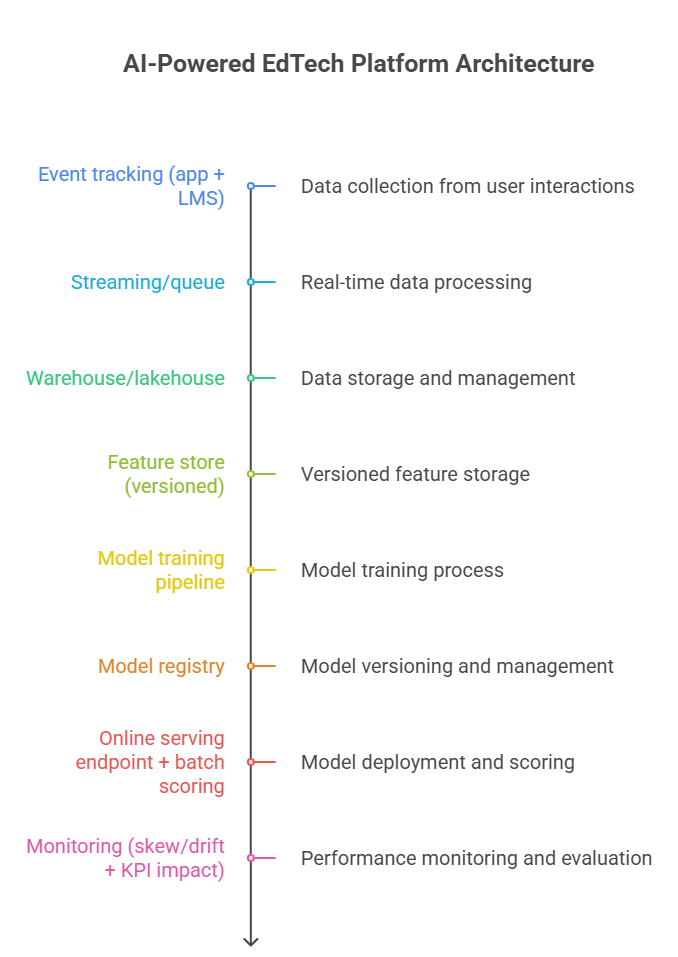
Google’s MLOps reference architecture is useful here because it treats monitoring as a first-class stage and explicitly frames production monitoring as the trigger for pipeline reruns and new experiment cycles.
And for drift specifically, Google highlights practical monitoring of skew (training vs serving) and drift over time, which is exactly what breaks EdTech models when cohorts, curricula, or seasonality shifts.
Ship the smallest “decision loop” that moves one KPI, instrument it, and only then expand model scope.
Overengineering usually happens when teams build a complex AI platform before validating that the model can reliably change learner behavior or reduce ops cost.
Checklist (MVP AI rollout under 6 months):
Before you ship features, validate where AI should actually make decisions—progression, assessment, or intervention.
Talk to AppVerticalsRealistically, the cost is driven less by “AI models” and more by product integration: data pipelines, evaluation, guardrails, and ongoing inference at scale.
That’s why budgets swing so widely between “pilot that looks good” and “production system that holds up.”
McKinsey’s latest global survey is a good reality check: only 39% of organizations report enterprise-level EBIT impact from AI, even though many report use-case benefits, meaning a lot of spend still fails to translate into measurable business impact.
To make costs predictable, treat AI as three line items: build + integrate, run (inference/compute), and maintain (monitoring/retraining/governance).
The tier difference is mostly about integration depth and governance, not “smarter AI.”
| Company stage | Typical scope that actually works | Typical build budget (project) | Ongoing run cost drivers |
|---|---|---|---|
| Startup (Seed–Series A) | 1–2 decision loops (e.g., adaptive progression + feedback), minimal integrations | $60k–$180k | Token usage, logging, lightweight monitoring |
| Scale-up (Series B–C) | Multi-cohort personalization + analytics, LMS/CRM integrations, evaluation harness | $180k–$450k | Higher usage + A/B testing, drift monitoring, stronger guardrails |
| Enterprise / modernization | Legacy data unification, compliance controls, multi-region rollout, MLOps | $450k–$1M+ | Governance + auditability + monitoring at scale; security/compliance overhead |
What this table really shows is how AI shifts the education app development cost in 2026 curve: the spend increases as products move from pilots to production, not because models are more advanced, but because reliability, compliance, and scale become non-negotiable.
Gartner forecasts worldwide AI spending at $2.52T in 2026, driven heavily by infrastructure and software, meaning the market is pricing in “production AI,” not cheap experiments.
Phase AI as “prove impact → harden systems → scale safely,” because most orgs don’t get enterprise EBIT lift without disciplined execution.
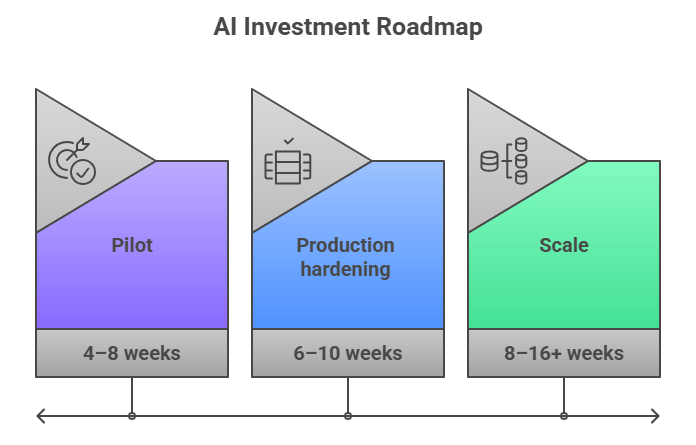
It’s cheaper to build in-house only if you already have strong data + MLOps maturity; otherwise partnering is usually cheaper in time-to-value and rework avoided.
| Option | When it’s cheaper | Hidden costs to watch |
|---|---|---|
| In-house build | You already have data pipelines, evaluation discipline, and product ownership for AI | Hiring and retention costs, ramp time, and “almost-right” models shipped without monitoring |
| Staff augmentation | You need speed but can own architecture and governance internally | Coordination overhead; continued need for an internal AI product owner |
| Specialized delivery partner | You need end-to-end execution (data → model → integration → monitoring) on a deadline | Vendor lock-in risk if pipelines, evaluations, and documentation aren’t transferable |
76% of developers say they’re using or planning to use AI tools in their development process, like teams are already augmenting engineering with AI, but that doesn’t remove the need for strong delivery discipline in production AI.
The biggest risks are predictable: messy or unrepresentative learning data, model behavior you can’t reliably audit in production, and privacy/compliance exposure across regions.
For most EdTech teams, the risk isn’t “AI goes wrong once.” It’s that AI quietly becomes an ungoverned decision-maker inside learning and assessment flows, while usage scales faster than oversight.
Here’s the risk matrix I see most often in real rollouts:
Risk matrix (what actually breaks production AI in EdTech):
And don’t ignore governance/security costs when you scale. IBM reports the global average cost of a data breach is $4.4M, which is why mature AI rollouts budget for monitoring and controls early.
They reduce accuracy in the exact places your product is judged: assessment decisions, progression logic, and intervention triggers, because bias and data gaps show up as “wrong outcomes,” not just lower model scores.
In EdTech, bias usually enters through who your data represents (regions, languages, learning needs), how outcomes are labeled (what “mastery” means), and how feedback is generated (tone, appropriateness, and correctness).
UNESCO’s guidance on generative AI in education explicitly flags risks like fabricated information, improper handling of data, privacy breaches, unauthorized profiling, and bias.
Risk chart (common bias/data failure modes):
They map data types and model behavior to the strictest applicable rules, then design one policy/architecture that satisfies all, instead of maintaining a different “AI” per region.
For your ICP (North America, Europe, GCC, Australia), the baseline reality is: you’re often dealing with student/learner data, and the compliance bar is high.
Table (what “compliance alignment” means in practice):
| Region / Framework | What It Forces You to Do | Practical AI Implication |
|---|---|---|
| US (FERPA) | Controls disclosure of personally identifiable information from education records; gives rights to access/amend and limits disclosure | Treat learner records as regulated; lock down model training data and sharing paths |
| EU (GDPR) | Legal basis for processing, data minimization, purpose limitation, access/erasure rights, and cross-border transfer controls | Build region-aware data handling, retention policies, and audit trails for AI decisions |
If you’re operating multi-region, the most important “non-obvious” move is keeping a provable data lineage: what went into training, what was used at inference, and who accessed it, because that’s what turns compliance into something you can audit.
You mitigate AI risk by making model behavior testable, reviewable, and reversible, before you expose it to real learners.
The cleanest structure I’ve found is to use an established risk framework and turn it into a release gate. NIST’s AI Risk Management Framework (AI RMF) is designed for exactly this: GOVERN, MAP, MEASURE, MANAGE.
Checklist (pre-launch AI risk audit):
AppVerticals helps EdTech companies move from proof-of-concept to production scale by unifying product strategy, data readiness, and execution, turning early AI experiments into systems that deliver measurable operational value.
AppVerticals has built unified digital learning platforms that automate enrollment, course delivery, and engagement across regions, such as the Nokia Al-Saudiah Training Center project, a foundation that supports advanced AI features like personalization and adaptive pathways.
AppVerticals delivers AI projects by starting with real learner behavior outcomes and engineering data pipelines, decision logic, and guardrails up front, not as an afterthought.
AppVerticals bridges that gap through a disciplined delivery lifecycle, including discovery, data readiness, integration, and monitoring, ensuring the AI you ship changes the product rather than sits on the shelf.
Proof points:
This approach means your AI investment doesn’t stall in experimentation. It becomes part of the product’s backbone.
With 200+ custom education software development solutions serving 20M+ learners, AppVerticals brings deep EdTech deployment experience that ensures AI systems are integrated into robust, scalable products, not just prototypes.
EdTech companies should partner when they need to accelerate time-to-market, fill talent gaps, or embed AI into core flows without ballooning internal headcount.
Partnerships are especially effective when:
This doesn’t mean outsourcing oversight. It means getting the strategic + technical leverage you need to ship AI where it matters.
AI in EdTech now fails or succeeds based on execution, not ambition. Teams that get results are explicit about where AI is allowed to make decisions and realistic about the cost, governance, and risk of running models in live learning environments.
What separates outcomes isn’t smarter models, but operational maturity: clean data pipelines, measurable decision loops, hybrid architectures that control cost and latency, and compliance that holds across regions. Prove impact one decision at a time, then scale.
AppVerticals helps teams design, integrate, and scale AI where it delivers measurable learning and business outcomes.
Discuss with AI Expert
verified expert
Muhammad Adnan is a Senior Writer and Editor at AppVerticals, specializing in apps, AI, software, and EdTech, with work featured on DZone, BuiltIn, CEO Magazine, HackerNoon, and other leading tech publications. Over the past 6 years, he’s known for turning intricate ideas into practical guidance. He creates in-depth guides, tutorials, and analyses that support tech teams, business leaders, and decision-makers in tech-focused domains.
 We’re AppVerticals
We’re AppVerticals
AppVerticals is where innovative startups and Fortune 500s come for transformation.
View About Us Industry
Industry
Ever waited hours for a truck to arrive, only to find out the shipment was delayed, rerouted, or worse, lost in paperwork? Frustrating, isn’t it? That...
14 min read
 EdTech
EdTech
Most enterprise learning platforms don’t collapse overnight. They slowly stop serving the teams relying on them. What begins as a smart, tactical solu...
16 min read
 Industry
Industry
The logistics industry is undergoing a massive digital shift. From on-demand trucking apps to AI-powered delivery logistics apps, businesses are relyi...
11 min read
Discover how our team can help you transform your ideas into powerful Tech experiences.
AppVerticals © 2026 | All Rights Reserved
Get In Touch.














 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Google AI
Google AI


