













 ChatGPT
ChatGPT
RAG and fine-tuning are two ways to customize a large language model and the difference is simple: RAG gives the model new knowledge, while fine-tuning changes its behavior. Retrieval-augmented generation (RAG) connects a model like GPT-4 or Claude to an external knowledge base or vector store like Pinecone and retrieves relevant facts at query time. Fine-tuning instead retrains the model’s weights on your examples so it adopts a specific tone, format or task.
Start with RAG when knowledge changes often, fine-tune when you need consistent behavior and combine both when you need accurate facts in a controlled style.
Key Takeaways
- RAG gives the model new knowledge while fine-tuning changes how it behaves.
- RAG gives the model new knowledge while fine-tuning changes how it behaves.
- Start with RAG by default as it is faster, cheaper and more accurate than fine-tuning for most production use cases.
- Fine-tune only when the gap is behavioral, such as tone, format or a specialized task prompting cannot fix.
- RAG reduces hallucinations better because it grounds answers in retrieved sources that the model can cite.
- Combining RAG and fine-tuning is now the standard pattern, with RAG owning the facts and fine-tuning owning the delivery.
- Fine-tuning front-loads a higher cost while RAG converts a lower upfront investment into a steady per-query expense.
- Most production failures trace back to ungoverned data, stale weights or a missing evaluation baseline, not the model itself.
What is RAG and How Does it Work?
RAG is an architecture that lets a language model answer using information it was never trained on, by fetching that information at the moment of the query. Instead of relying only on what the model memorized during its original training, a RAG system searches an external knowledge source, pulls back the most relevant passages and hands them to the model as context alongside the user’s question. It is the approach I reach for first on most projects and the reasons become clear once you see how the pipeline runs.
How a RAG pipeline works step by step
The mechanics are more straightforward than the acronym suggests. First, your source content, which might be support articles, internal policies, product documentation or database records, is broken into smaller passages through a process called chunking. Each chunk is then converted into a numerical representation called an embedding and stored in a vector database such as Pinecone, Weaviate, Qdrant or pgvector for teams already running PostgreSQL.
When a user asks a question, the system embeds that question, searches the vector database for the passages whose embeddings are closest in meaning and injects the top matches into the prompt. On nearly every system I build now, I add one more step before that injection, called reranking, where a second and more precise model re-scores the handful of candidate passages and pushes the genuinely best match to the top rather than trusting the raw similarity order.
In my experience this is one of the highest-impact accuracy levers available, with current benchmarks pointing to improvements in the range of 15 to 35 percent over embedding-based retrieval alone, which is why I treat it as part of the build rather than an optional extra. The model then generates an answer that is grounded in those retrieved and reranked passages rather than in its frozen training data.
What is Fine-Tuning and How Does it Work?
Fine-tuning is the process of continuing a model’s training on a curated set of your own examples so that its underlying weights shift toward the behavior you want. Where RAG leaves the model untouched and feeds it information at query time, fine-tuning permanently alters the model itself. The result is a model that has internalized a particular tone, format or task and that produces it consistently without needing to be reminded in every prompt. I turn to it when off-the-shelf behavior is not good enough and prompting alone cannot close the gap.
How fine-tuning works in practice
In practice, a fine-tuning project starts with assembling a dataset of high-quality input and output pairs that demonstrate exactly how you want the model to respond. That dataset has to be clean, representative and large enough to move the model’s behavior without overfitting it to a narrow set of phrasings. The examples are then used in a training run that adjusts the model’s parameters, after which I evaluate the new version against held-out data to confirm it learned the intended behavior rather than memorizing the training set. I rarely retrain every weight in the model. Like most teams today, I use parameter-efficient methods such as LoRA, which update a small set of additional parameters and dramatically reduce the compute and cost involved while preserving most of the benefit.
What fine-tuning gives you and what it does not
What you get from fine-tuning is consistency. A fine-tuned model can reliably produce structured output in a fixed format, adopt a brand voice across thousands of interactions or handle a specialized classification task that the base model fumbles. What you do not get is fresh knowledge. The model’s understanding is frozen at the moment of training, so when your underlying facts change, the only way to update the model is to curate new examples and run the training process again. That single property, knowledge frozen at training time, is the reason I find fine-tuning and RAG so often end up solving genuinely different problems.
RAG vs Fine-Tuning: The Key Differences at a Glance
The cleanest way I know to see the distinction is to put the two approaches side by side across the dimensions that actually drive an architecture decision. The table below summarizes what each method changes, what it is best suited to and where each one starts to break down.
| Dimension | RAG | Fine-Tuning |
|---|---|---|
| What it changes | What the model knows | How the model behaves |
| Best for | Fresh and changing facts, Q&A over documents | Consistent tone, format or a specialized task |
| Data freshness | Live, updated by changing the knowledge base | Frozen at training, requires retraining to update |
| Upfront cost and effort | Lower, typically days to weeks | Higher, requires curated data, compute and ML skills |
| Ongoing maintenance | Vector database plus retrieval costs per query | Periodic retraining as data drifts |
| Hallucination control | Stronger answers are grounded in citable sources | Weaker, no factual grounding, so confident answers can still be wrong |
| Latency | Adds a retrieval step to every query | Fast, no retrieval at inference time |
| Data and expertise | Clean knowledge base plus a chunking strategy | Labeled examples plus genuine ML expertise |
| When to avoid | Behavior or formatting problems | Fast-changing or auditable knowledge |
The single most useful line in that table is the first one. RAG changes what the model knows and fine-tuning changes how the model behaves. Almost every other difference flows from that distinction. Because RAG injects information at query time, it stays current and it can cite sources, which is why it controls hallucinations better.
Because fine-tuning bakes behavior into the weights, it is fast at inference and consistent in style but it cannot give the model a fact it was not trained on. When someone asks me which approach is better in the abstract, I tell them the question itself has already taken a wrong turn, because the two are answering different questions.
RAG vs Fine-Tuning vs Prompt Engineering: Where Each Fits
Before I commit a team to either RAG or fine-tuning, I place both alongside the cheapest customization technique of all, which is prompt engineering. These three approaches sit on a spectrum of effort and permanence and choosing well usually means starting at the lightest end and only moving up when the lighter option genuinely falls short.
Where prompt engineering fits
Prompt engineering is the practice of shaping the model’s output purely through the instructions and examples you put in the prompt. It changes nothing about the model and adds no infrastructure, which makes it the fastest and least expensive option by a wide margin. For many tasks, a well-constructed prompt with a few worked examples is enough to get the behavior you want and I have watched teams reach for heavier machinery before testing whether careful prompting would have solved the problem.
The limitation is that a prompt has a finite context window and no memory, so it cannot inject a large and changing body of knowledge and it cannot reliably enforce a behavior across every edge case the way a trained model can.
Why these three Layers aren’t Rivals
RAG sits one level up. It solves the knowledge problem that prompting cannot because it can search across a knowledge base far larger than any prompt could hold and surface only the passages that matter for a given question. Fine-tuning sits at the most permanent end of the spectrum because it changes the model itself and is therefore the right tool when you need a behavior or a skill to be reliable and built in rather than requested each time.
The sequence I follow on most engagements is to push prompt engineering as far as it will go, add RAG when the model needs knowledge it does not have and fine-tune only when consistency of behavior is still the gap after the first two are in place. These techniques are layers, not rivals and the strongest production systems I have shipped frequently use all three at once.
Cost and Effort: Is Fine-Tuning More Expensive than RAG?
Most published comparisons wave a hand at this question and conclude that fine-tuning costs more, without ever putting numbers on the table. That is the gap I want to close here, because the real cost of each approach is the single factor that most often decides which one a team can actually ship. In my experience fine-tuning usually carries a higher and lumpier cost, while RAG carries a lower upfront cost that converts into a steady operational one.
The table below frames the comparison the way it tends to play out on real delivery, using engineer-weeks and ongoing maintenance rather than vague adjectives.
| Factor | RAG | Fine-Tuning |
|---|---|---|
| Typical build effort | Roughly 2 to 6 engineer-weeks for a production-grade pipeline | Roughly 6 to 12+ engineer-weeks, including data curation and iteration |
| Largest upfront cost driver | Data ingestion, chunking strategy and retrieval quality tuning | Curating and labeling a clean training dataset, plus computing for training runs |
| Specialized skill required | Data engineering and retrieval evaluation | Genuine ML expertise for training, evaluation and overfitting control |
| Ongoing cost shape | Recurring vector database hosting plus embedding and retrieval costs per query | Periodic retraining runs as the underlying data drifts |
| How cost scales | Grows with query volume and knowledge-base size | Grows in steps with each retraining cycle |
How the cost pattern actually plays out
The pattern underneath those numbers is what matters. Fine-tuning front-loads its cost because the expensive parts, which are curating the dataset and running and validating the training, all happen before you see any benefit and that entire cost recurs every time your requirements or your data change enough to warrant a fresh run. RAG inverts this.
The build is lighter and faster to stand up but it introduces a permanent operating cost in the form of vector database hosting and a per-query retrieval charge that grows directly with usage. Over a long horizon, I find RAG tends to be cheaper for knowledge that changes frequently because you never pay to retrain, whereas fine-tuning can pay off for a stable, high-volume task where the behavior is fixed and the per-query inference is fast and retrieval-free.
If you want to model these trade-offs against the broader build budget, our guide to software development cost estimation is a useful companion when scoping either path.
Accuracy and Hallucinations: Which is More Reliable?
For factual accuracy, I trust RAG as the more reliable approach and the reason is structural rather than incidental. The distinction matters most in exactly the applications people build first, which are the ones where a wrong answer carries a real cost.
Why does RAG control hallucinations better?
When a model answers from retrieved source documents, it is grounding its response in material it can point to, which both reduces the chance of fabrication and makes any fabrication that does occur far easier to catch. A RAG system can return citations alongside its answer, so a reviewer or an end user can verify the claim against the source instead of trusting the model’s memory.
For any application where the answer has to be accurate and current, I consider that grounding the strongest defense against hallucination available short of a human in the loop.
Where fine-tuning falls short on accuracy
Fine-tuning does not offer the same protection and it is important to be precise about why. Fine-tuning improves how consistently a model behaves but it does not give the model new facts, so a fine-tuned model can still produce a confidently wrong answer when it is asked about something outside its training data.
In fact, I have seen fine-tuning make a model more fluent and assured in its phrasing, which has the unwelcome effect of making its incorrect answers sound more authoritative. The behavior improves while the factual grounding does not and that combination is exactly the failure mode that gets missed in testing and discovered in production.
How combining both produces the most reliable system
This does not mean fine-tuning has no role in reliability. A fine-tuned model can be more consistent at refusing to answer when it is uncertain or at adhering to a format that surfaces its reasoning, both of which support trustworthy output.
The cleanest reliability story I know, though, comes from combining the two: use RAG to supply accurate and current facts and use fine-tuning to enforce the disciplined, well-formatted way those facts are delivered. When accuracy is the priority and the knowledge is changing, I treat RAG as the safer default and fine-tuning as the refinement layer rather than the foundation.
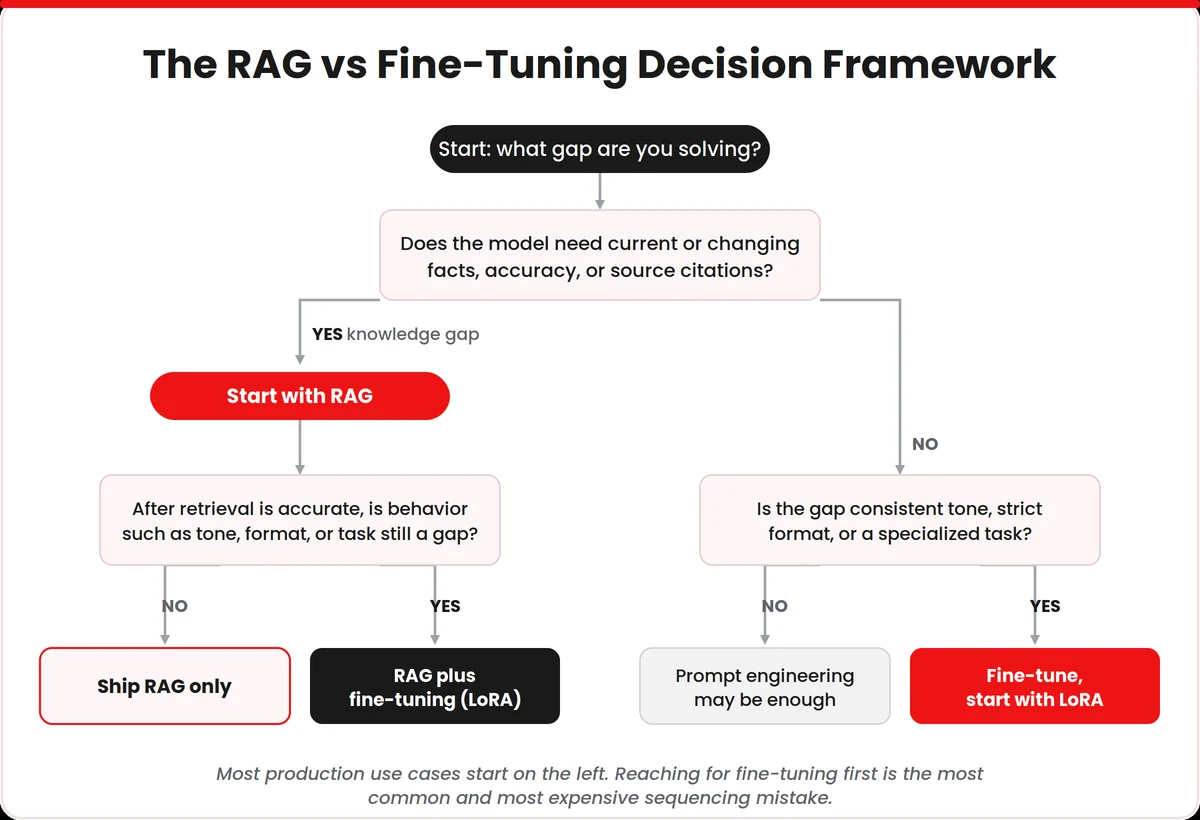
When to Use RAG, Fine-Tuning or Both: The Decision Framework
Most guides end the comparison here and leave you to weigh the trade-offs yourself. I think that is a cop-out, because after enough real projects, a clear default emerges. So rather than restating the trade-offs one more time, here is the position I actually take with clients, expressed as a framework you can apply to your own use case.
The RAG vs Fine-Tuning Decision Framework
Not sure which approach fits your use case?
Most teams waste weeks on fine-tuning before confirming the problem is even behavioral. Talk to our AI team and we’ll tell you in one conversation which path makes sense for your build and which one to skip.
Start with RAG by default:
For the large majority of production use cases, RAG is the right first move because it is faster to build, cheaper to validate, easier to keep current and stronger on accuracy and auditability. If your knowledge changes often, if your answers have to stay accurate or if you need to cite sources, RAG is not just an option, it is the starting point. The cost of being wrong here is low, since a RAG prototype can be standing up and answering against your real data in days rather than weeks.
Fine-tune when the gap is behavior, not knowledge:
I move to fine-tuning when the problem I am left with is how the model behaves rather than what it knows. The clearest signals are a need for a consistent tone or brand voice across every interaction, a strict output format that prompting cannot reliably enforce or a specialized task that the base model handles poorly, no matter how good the prompt is.
If you find yourself fighting the same behavioral problem across thousands of responses, that is the point where the permanence of fine-tuning earns its higher cost.
Combine both when you need accurate facts delivered in a controlled style:
This is no longer a niche or advanced-only choice. It is now the standard production pattern, with roughly 60 percent of production deployments using both RAG and fine-tuning together, according to 2026 industry analysis.
The division of labor is clean. RAG owns the facts and fine-tuning owns the delivery. The textbook case I point to is a support assistant that pulls the correct, current policy and then delivers it in a precise, on-brand and compliance-safe format. Most teams reach this setup by proving RAG first and layering fine-tuning on top, which is the order I recommend in the next section.
If you want this framework applied to a specific use case rather than in the abstract, that is exactly the kind of scoping my team works through in our AI development services before any build begins.
Production Reality: Three Failure Patterns and How to Prevent Them
The comparison so far describes how these approaches behave when they work. The more valuable question for anyone about to commit budget is how they fail, because production is where most of these projects run into trouble. Gartner has reported that 30% of generative AI proofs-of-concept are abandoned before they ever reach production, with data quality, cost and unclear return on investment cited as the recurring causes.
That number describes generative AI as a whole rather than RAG specifically and it should not be read as a RAG failure rate, but it sets the right expectation. The distance between a promising demo and a system that holds up in production is wide and in my experience it is rarely the model that closes it.
The RAG-specific picture is better documented than most teams realize. Barnett et al. (2024), in their failure taxonomy of retrieval-augmented generation systems, classify the concrete ways these pipelines break once real users and real data are involved. The three patterns below are the ones I see most often in delivery work, drawn from that research and from my own client engagements. I name each one, because naming a failure is the first step to designing it out.
Pattern 1: Retrieval against ungoverned data
What causes it:
A RAG system is only as trustworthy as the knowledge base it retrieves from and most knowledge bases were never built to be retrieved from. When the underlying content contains stale documents, near-duplicate versions of the same policy or mislabeled files, the retriever does its job perfectly and still hands the model the wrong source. Barnett et al. identify this retrieval-against-ungoverned-data problem as the most common RAG failure mode in production and it almost never shows up in a demo because demos run against a small and carefully curated set of clean documents.
What it looks like in production:
The model answers fluently and confidently and the answer is wrong, because it faithfully summarizes a superseded document or blends two conflicting versions of the same policy. To the user, it looks like the model lied. In reality, the retrieval layer surfaced bad source material and the model had no way to know.
How my team prevents it:
We run a data-readiness audit before a single retrieval query is written, because the order of operations matters here. In our delivery work, I have seen this pattern surface in 60% of client handoffs where RAG was selected before anyone checked whether the knowledge base was actually governed. The fix is unglamorous and decisive: deduplicate and version the source content, assign clear ownership for each document set and add relevance filtering and source-recency rules to the retrieval layer so that stale or low-confidence passages never reach the context window in the first place.
Pattern 2: Fine-tune weight overconfidence
What causes it:
Fine-tuning bakes knowledge into the model’s weights at a single moment in time and those weights cannot update themselves afterward. When a team fine-tunes on domain data that was accurate at training time but has since moved on, the model keeps answering with the same confidence it always had, except the answers are now wrong. I find this most damaging in fast-moving domains such as pricing, policy and product specifications, where the facts change faster than anyone schedules a retraining run.
What it looks like in production:
A fine-tuned support or sales model quotes a price, a policy or a specification that was correct last quarter and is wrong today and it does so with complete assurance. Because the behavior of the model has not changed and only the world has, the problem is invisible to anyone testing the model’s tone or format. It surfaces instead as a customer acting on outdated information.
How my team prevents it:
We treat anything that changes faster than the retraining cadence as a knowledge problem rather than a behavior problem, which means it belongs in RAG and not in the weights. When a use case genuinely needs both, we fine-tune only the stable behavior and let RAG supply the volatile facts, so that a price change or a policy update becomes a knowledge-base edit rather than a training run. We also set an explicit retraining trigger tied to how quickly the domain data drifts, so the model is never quietly out of date.
Pattern 3: The missing evaluation baseline
What causes it:
The most expensive failure pattern is also the quietest. Teams stand up a RAG or fine-tuned system, run a handful of demo queries, see good answers and declare it working, all without ever building a fixed test set of real questions with known-good answers. With no baseline, there is no way to measure whether the system is getting better or worse over time and drift becomes invisible.
What it looks like in production:
Everything seems fine at launch and then quality erodes slowly as the knowledge base grows, the data drifts or query patterns shift. Nobody notices because nobody is measuring, until a user complaint or a visible mistake forces the kind of investigation that should have been running automatically all along.
How my team prevents it:
We build the evaluation set before the system ships rather than after, scoring accuracy, relevance and hallucination rate against known-good answers. For RAG we measure retrieval quality as its own separate metric, because you cannot fairly judge an answer until you know whether the right document was even returned. For fine-tuning, we test against held-out data to catch overfitting. Most importantly, the evaluation runs continuously in production rather than once at launch, so that drift and wrong answers are caught by the monitoring rather than by the customer.
If I had to name the single most common and most expensive mistake I see, it is reaching for fine-tuning when the actual problem is a knowledge problem that RAG would have solved in a fraction of the time. Teams spend weeks curating training data and running experiments and they end up with a model that sounds polished but still cannot answer accurately, because the facts were never the model’s to memorize in the first place. Starting with retrieval would have gotten them to a working system faster and it would have shown them exactly what, if anything, was left for fine-tuning to fix.
Final Thoughts
The choice between RAG and fine-tuning is not really a competition, it is a question of what you need the model to do. If you need accurate and current knowledge, start with RAG. If you need consistent behavior or a specialized skill, fine-tune. And for most production systems, I expect you will combine them, with RAG supplying the facts and fine-tuning controlling how those facts are delivered. Once you know your use case and you understand your data, the right approach is usually clear and for a wider view of where AI is paying off in real products, see our roundup of AI in app development statistics.
The teams I see get this right are rarely the ones with the most sophisticated stack. They are the ones who started with the lighter, cheaper, more accurate option, proved it against their real data and only added complexity when the evidence told them to.
Building a RAG or fine-tuned system?
Get expert guidance from our AI development team.